Models
Model Parameter Counts
Section titled “Model Parameter Counts”o1: 27.5B active, 650B total (same as GPT-4o)
o1-mini: 2.35B active, 55.5B total
o3-mini: 3.5B active, 162B total
GPT-4o mini: 3.44B active, 81.5B total
GPT-4o: 27.5B active, 650B total
GPT-4.5: 317.6B active, 17.2T total
Odyssey Deal
Section titled “Odyssey Deal”
Areas of Expertise that Certain Models Have Been Trained in
Section titled “Areas of Expertise that Certain Models Have Been Trained in”
The Product-driven Research Loop
Section titled “The Product-driven Research Loop”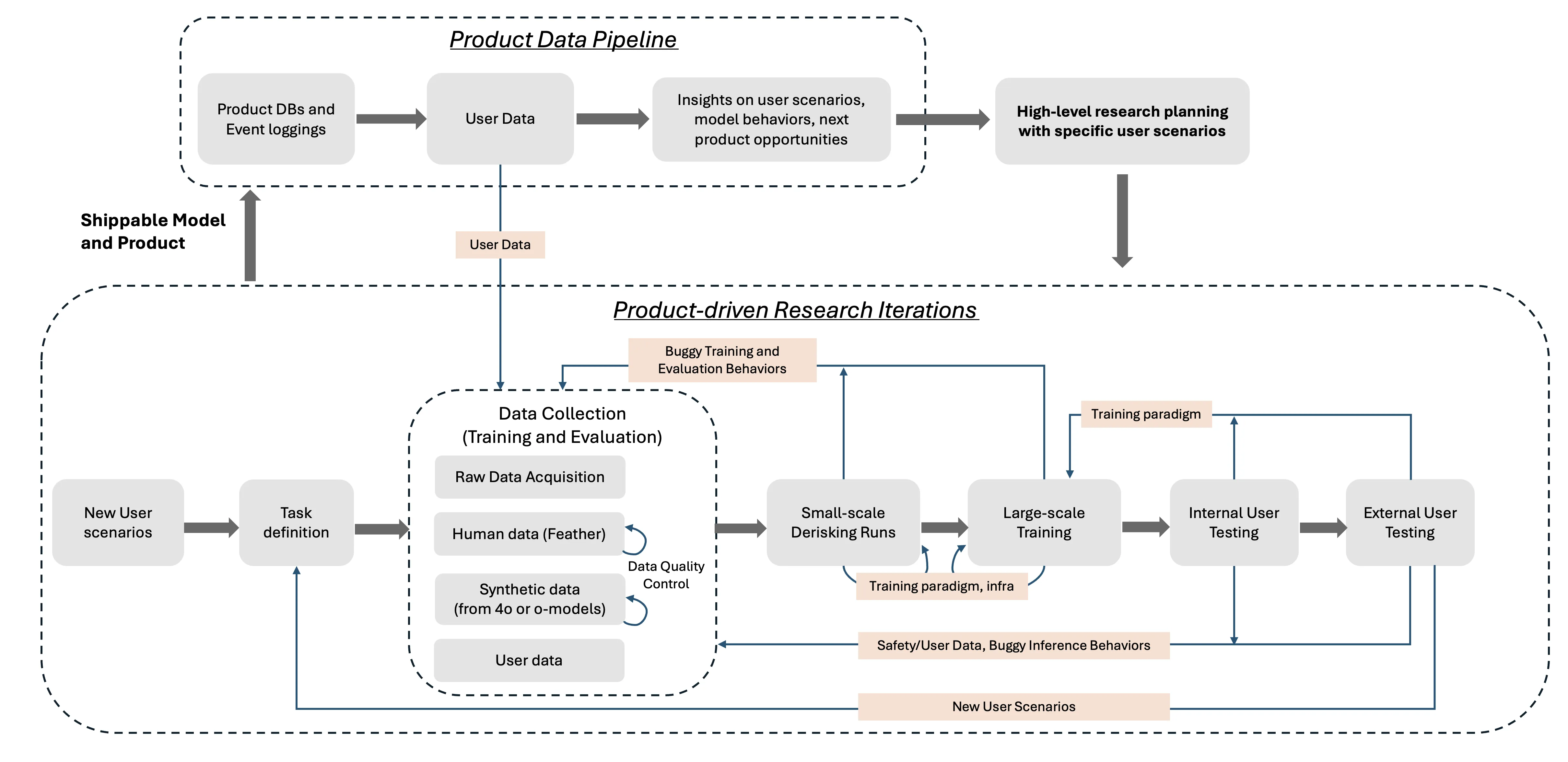


| Company | Model | Type | Date added |
|---|---|---|---|
| Nari Labs | Dia2 | Real time text-to-speech | 2025 Journal |
| Mistral | Mistral 3 + Ministral 3 (Gemma compete) | Mistral unveiled the Mistral 3 family: one open-weight frontier model (Mistral Large 3) plus nine smaller “Ministral 3” models spanning 14B, 8B, and 3B parameters in Base, Instruct, and Reasoning variants. Large 3 is a multimodal, multilingual model using a granular Mixture of Experts with 41B active parameters out of 675B total and a 256k context window, positioned for document analysis, coding, AI assistants, and workflow automation. | 2025 Journal |