mmc.vc - Agentic Enablers Treating AI’s amnesia and other disorders
19.11.25
Agentic Enablers
Section titled “Agentic Enablers”Between ourselves and ChatGPT, we were able to list out more than 100 Hollywood movies that involve memory loss as a major plot point, everything from Memento to 50 First Dates to Eternal Sunshine of the Spotless Mind.
Similarly, AI agents’ amnesia and other disorders (like hallucination) are a central plot point in this research piece. We asked ourselves:
- How do we get AI agents to stop hallucinating, and achieve higher accuracy?
- How do we make sure they continuously learn, retain this knowledge and improve as they gain more experience over the course of their deployment?
- How can we get truly personalised AI agents?
The answer lies in context and memory management. More specifically:
- Context Portability solutions that enable your preferences to follow you across platforms, so you can have personalised AI agents;
- Search APIs that give agents access to accurate, relevant, up-to-date and trustworthy information from external sources; and
- Knowledge Graphs and Ontologies that structure proprietary internal knowledge in way that makes AI agents reliable and explainable.
In this report, we explore in detail how these technologies lead to more capable AI agents, as well as the startups building in this space.
Unlike most AI agents (as they stand today) we’re able to continuously learn, so if you’re a founder building in the context and memory management space, we’d love to know more about how you’re powering the new agentic paradigm – please reach out to Advika or Sevi.
What Are Context and Memory? And why Do We Need Them?
Section titled “What Are Context and Memory? And why Do We Need Them?”Context is an AI agent’s short-term working memory – it’s the immediate information available during inference, like computer RAM. It’s limited, costly to maintain, and resets between sessions, but directly shapes the model’s responses. Memory, on the other hand, is long-term storage – persistent information kept outside the model that must be retrieved to influence outputs. Memory is key because it enables AI agents to learn and improve over time, as they adapt their behaviour in response to accumulated experience. Given the focus of our research, here’s a fun mnemonic device to summarise why your AI agents need context and memory management: APE, which stands for A ccuracy, P ersonalisation, E volution.

Accuracy: Too much Data, or not Enough
Section titled “Accuracy: Too much Data, or not Enough”Recently, Deloitte partially refunded the Australian government over an AUD $440k report, after admitting that AI had been used in its creation… because it contained several hallucinations (including three nonexistent academic references and a made-up quote from a Federal Court judgement).
It’s bad enough when a simple LLM hallucinates, but it’s worse in the case of multi-agent systems where a faulty or hallucinated output from one agent can propagate throughout the system, triggering error cascades where downstream agents may build up on that misinformation, and in the process compromise the entire system.
The accuracy problem with AI agents has two dimensions (a classic Goldilocks problem, if you will):
- Not enough data, so they make up things (typically triggering ‘hallucination’); or
- Too much data, so they get distracted, overwhelmed and confused, which makes them less reliable and accurate (a phenomenon called ‘context rot’)
Not enough data: Hallucinations and the lack of humility
LLMs only know what they were trained on, so they miss new, domain-specific, or proprietary information and may hallucinate – which is why they need external, real-time knowledge sources to stay accurate and reliable.
OpenAI’s recent research shows that LLMs hallucinate partly because current evaluation methods don’t reward models enough for humility; they effectively reward guessing over honesty, discouraging expressions of uncertainty. Improving this means rewarding “I don’t know” and giving models accurate, timely data – but not so much that they become overloaded.
Too much data: Context rot affects your bot
The context window determines how much content the AI model understands together at one time. The larger the context window, the more the model can read and understand. Today models have million token plus context windows (with 1 million tokens, the model can process about 1,500 pages of text at one go).
However, more content doesn’t necessarily translate into better performance. Context rot is the phenomenon where model accuracy and reliability declines as the input context length increases. For example, LLMs often exhibit a recency bias, as they disproportionately focus on later tokens (and lose track of earlier ones). Not to mention that they also lose important information buried in the middle of a long context (a phenomenon appropriately dubbed ‘lost-in-the-middle’). Going back to our earlier observation on hallucinations, as context length increases, models may get overloaded and react differently (GPT models often confidently give wrong answers, while Anthropic’s Claude falls silent or gives up). In short: giving it too much information worsens performance.
Besides the potential for distraction, you don’t want to load all your content into the context window because of costs. Token budgets are increasing for a few reasons:
- Reasoning models both consume and produce a lot of tokens. A reasoning model may use 5,000 tokens internally to generate a response with 100 tokens, and on average reasoning models’ response lengths are 8x longer vs non-reasoning models.
- Multi-agent systems may involve passing context between different agents, which increases overhead costs.
- Getting to the required level of reliability today may need multiple passes through the agentic system, which also increases token consumption.
This creates a Goldilocks problem: LLMs need context and memory that are precise, updated, and relevant – not too much and not too little – yet filtering, prioritising, and retaining exactly the right information is a notoriously hard balance to strike. This is exactly what practises like context engineering address, and the startups we talk about through the course of this report have made context engineering and memory management that much easier for us.

Personalisation: The Promise of Persistence and Context Portability
Section titled “Personalisation: The Promise of Persistence and Context Portability”Imagine having an AI agent work for you, and having to constantly remind it of your preferences. Frankly, it sounds exhausting and frustrating. But traditional LLMs are stateless, which means that they process each prompt in isolation without retaining previous context. This statelessness is what makes AI agents unable to perform robust long-horizon planning and execution (especially for complex, multi-stage tasks), unless their memory is externally managed.
AI memory startups like Cognee, Mem0, Zep and Letta are building systems that give AI persistent, evolving memory. They capture and organise information from user interactions and data streams into structured knowledge – often using graph-based or semantic layers – so AI agents can recall, update, and reason over past experiences. These platforms continuously refine what’s stored and retrieved, ensuring context stays relevant over time and enabling AI to learn and adapt dynamically, much like human memory.
Besides using AI memory to retain knowledge of prior interactions to deliver a better and more personalised user experience, there’s a fascinating new development: context portability.
If you think about your own digital life, so much about you is scattered across different platforms. Anthropic’s Claude knows how you like to code, Google’s Gemini knows what kind of styles and aesthetic you prefer when generating images, ChatGPT knows how you like your LinkedIn posts to be written, YouTube knows what videos you’ve watched, Amazon knows what you’ve shopped, Instagram knows which places you’ve holidayed in… you get the picture. So if you wanted ChatGPT to recommend a holiday destination for you, it would be far more useful for it to know whether you’re a mountains or beach kind of person (based on your Instagram pictures) or your hobbies and interests (based on your search history, YouTube videos, Instagram posts and so on).

Context portability is exactly what it sounds like: sharing context from one data controller (e.g. YouTube, Instagram, Amazon) to another (e.g. ChatGPT) so you have a better user experience with your personal AI agent. You could even use it to easily move your accumulated context from one AI provider to another (e.g. ChatGPT to Claude), so you have complete flexibility in which AI models you use. It’s like Open Banking, but for your digital data rather than your financial data. And much like Open Banking, the idea is that users are able to control, scope access to, use, and monetise their cross-platform data easily (particularly as the number of data sources increase). And startups like Fabric are making it that much easier for users to do so, by solving all the hard infrastructure challenges underneath.
From a regulatory perspective, GDPR Article 20 provisions for data portability, including “the right to have the personal data transmitted directly from one controller to another, where technically feasible,” and Digital Markets Act Article 6(9) establishes the gatekeepers’ obligation to provide end users with effective data portability. Similarly, UK’s Smart Data Scheme is a framework that allows customers to securely share their data with authorised third parties to get better services. Startups such as Fabric and Vypr are leveraging context portability to give users more personalised experiences securely, and at the same time aligning with emerging data rights and regulatory frameworks. While Fabric focuses on better AI experiences, and Vypr focuses on agentic commerce, we see both leveraging context portability.
Evolution: Better, More Capable AI
Section titled “Evolution: Better, More Capable AI”A recently published research paper on The Definition of AGI dissected general intelligence into ten core cognitive domains – including reasoning, memory, and perception. The findings were telling: While proficient in knowledge-intensive domains, current AI systems have critical deficits in foundational cognitive machinery, particularly memory. As the paper notes, “Without the ability to continually learn, AI systems suffer from ‘amnesia’ which limits their utility, forcing the AI to re-learn context in every interaction.” We’ve added a chart from the research paper which shows just how “jagged” and lopsided AI development has been to date.

Memory and context issues can affect AI’s reasoning in surprising ways. Let’s take the issue of context distraction (when the context is so long that the model focuses on pattern-matching from past interactions, rather than reasoning about the current situation, even when past actions are unsuitable for the current problem) – something that was observed with Gemini 2.5 Pro (which can technically handle over 1 million tokens, but when the context grew beyond 100,000 tokens, the agent tended to repeat past actions instead of creating new plans).
Or another issue is where your AI Agent’s accumulated context and memory contains contradictory information – not all information is equally reliable, or even equally fresh. As humans, we are blessed with the power of forgetfulness, where gradually the older, less relevant, and less reliable information fades away – but AI agents don’t have that capability. This gives rise to contradictions that lead to a loss in decision-making skills, and is hindering our advancement towards more capable AI systems.
The goal is to get to AI agents that don’t just learn during training, but continue to learn while on deployment – much like how a human colleague learns about the business, their team’s preferences and work styles, and remembers previous mistakes to avoid repeating them. All this learning affects future behaviour, which makes context and memory management an issue of paramount importance. This means that AI memory needs to be adaptive, i.e. evolving with business needs, re-prioritising as needed and continuously updating.
With all this context in place, it’s time to dive right into some of the technologies supporting this today – Search APIs, Knowledge Graphs, and Ontologies.
Let’s say you’re a developer and you want fast, reliable access to accurate, relevant, and up-to-date results for your AI Agents. There are two ways in which you could give your AI model access to the web today:
- The common way: You’re likely using a SERP API (Search Engine Results Page API) to scrape and retrieve real-time data from search engine results pages (e.g. Google, Bing). After scraping the pages, you’re de-duplicating the content, chunking it, re-ranking it, fact-checking it… and the list goes on.
- The easier way: It isn’t as hard as the common way, and you don’t have to write all that extra code, maintain scraping pipelines or spin up separate infrastructure. Search APIs are designed to help developers easily integrate search functionalities into their applications. It usually takes just a few lines of code.
Search APIs abstract away a lot of the complexity:
Building infrastructure at internet scale: The biggest challenge with building a Search API is re-indexing the internet at scale; you need embeddings for all the web pages, which makes this a massive infrastructure problem. That’s why Search API startups have typically started smaller (focusing on certain topics and use cases e.g. knowledge work) with very deep indexing rather than attempting to capture the entire internet, and then expanding coverage as they demonstrated reliability for certain topics/areas.
Establishing ground truth on the internet: The internet is a noisy place; you have to contend with SEO/GEO*, marketing pages, listicles, AI-generated blogs… and all other kinds of trash, so you need fact-checking. And there are also issues such as entity resolution, to make sure you’re retrieving genuinely relevant content. That’s why Search APIs provide domain filtering, so you can rely on trusted sources. They also provide in-line citations, so you get the source references directly in the text (and you can verify the information with a single click).
*We’re possibly part of the problem, because we wrote a popular guide on AI Discoverability: How can I get ChatGPT to recommend my brand? But we had pure intentions, we wanted startups to be successful in getting customers through this channel.
Making it AI-native and agent friendly: Three different areas of our current infrastructure are AI-unfriendly:
- Traditional search engines: These were built for humans, browsing 10 links at a time. But AI agents have very different needs; they need to look through multiple sources simultaneously, and legacy infrastructure that makes them scrape page-by-page introduces unnecessary friction in the process.
- Websites: As with search engines, websites were also designed for humans and have complex GUIs (graphical user interfaces) and while this visual environment works well for us humans, that’s not the case for AI agents. Cluttered layouts, advertisements, unlabelled buttons, excessive JavaScript that masks the content etc. all confuse AI agents. And most AI crawlers don’t render JavaScript content, which could make client-side rendered content invisible to AI. Agents need predictable, efficient retrieval, and Search APIs reduce the overhead of cleaning, parsing and filtering compared to generic web search.
- The raw outputs of scraping: Search APIs return data in structured formats (such as JSON) better suited for downstream processing by agents, rather than the unstructured formats typically returned by raw scraping. Also, Search APIs such as Linkup provide “search depth” options (standard vs deep) so you can choose quick responses or thorough research (for deep analysis tasks); traditional search engines typically don’t expose this as a parameter for agents.
Integrating multiple sources: Search APIs provide one clean endpoint that returns production ready context across different sources (market/financial data, research, news, web flows, custom databases), and integrating different sources is a much harder problem because these sources would have different dialects, auth flows, rate limits, mixed freshness and latency guarantees.
Providing precision with interpretability: Besides leveraging trusted sources and verifying citations, Search API providers such as Cala focus on providing precise context (e.g. if you asked “how many days does a landlord in California have to return a security deposit?” it comes back with a precise “21 calendar days”). This precision is critical; in our State of Agentic AI: Founder’s Edition survey we talked about how reasoning models consume and generate a lot of tokens, so infrastructure costs are mounting. And as we discussed earlier, giving an agent too much information confuses it (context rot) so you’re better off being as precise as possible. Because Cala uses knowledge graphs under the hood (we will discuss it shortly), it makes the web search results interpretable, so you can have clear provenance of data.

Observations
Section titled “Observations”Beyond the ease they bring to developers of agentic AI applications, Search APIs have significant implications for the content market and content marketing.
Given AI agents are able to parse so much more content than humans at one go, a single deep research query could potentially be very expensive. Imagine a situation where your agent needed access to 3 industry reports, but each report costs $4,000. And the worst part is, you didn’t even need all the insights featured in each report, maybe you just needed a single datapoint from each.
That’s why we believe that the content market will see a Great Unbundling, where you’re more likely to pay for exactly what you consume (otherwise you would choose not to consume it at all). And the reason you could (in many cases) choose not to pay for certain types of datasets is because AI agents can help you construct your own.
To illustrate: Rather than shelling out $50k per year for certain databases (e.g. for recruitment, sales leads), you could use AI agents (powered by Search APIs, of course) to construct your own. A lot of information is publicly available, but it’s time consuming and resource intensive to dig up and clean the data. However, AI agents could do all of that at a much lower cost. As a result of this, and with AI Agents (rather than humans) becoming the main consumers of content, we expect pricing strategies and business models for data providers to evolve.
That said, for specialist content (where it’s not easy to get the information publicly), Search APIs have partnered with premium sources for legally-cleared content (so you won’t be slapped with a copyright infringement lawsuit). For instance, Valyu has Rev Share Partner Programme (where the data rights holder earns every time an AI agent uses its content; Valyu supports attribution, tracking, and monetisation). In similar vein, Linkup powers Tollbit (which also helps publishers monetise content being consumed by AI). If you’re keen to learn more, we’ve previously talked about content partnerships and programmes in our research on Ethical AI: Moving from Napster to Spotify era.
Additionally, we think content delivery and content marketing will change as AI agents become the primary consumers of information; the data needs to be LLM-friendly. This means that a particular dataset/report needs to be marketed in such a way that the AI Agent thinks it is perfect for its use case, and that data needs to be delivered to it in a manner that’s easy for it to consume (e.g. using structured formats).
We’re fascinated by the changes that lie ahead, and AI agents (in particular, those powered by search APIs) are already playing an important role in reshaping the economic model for the internet.
Knowledge Graphs and Ontologies
Section titled “Knowledge Graphs and Ontologies”Search APIs are great for accessing web content, but what about your internal documents, proprietary knowledge of the business and deep domain expertise? That’s where AI agents would benefit tremendously from knowledge graphs and ontologies, because they give structure and meaning to data. This allows the AI to understand relationships rather than just words, and the structured context enables reasoning, consistency, and accurate decision making (something raw text or unstructured data alone can’t provide).
Knowledge Graphs (KGs) capture complex information by representing:
- Entities (Nodes) – e.g. Darth Vader, Luke Skywalker
- Relationships (Edges) – e.g. Darth Vader → FatherOf → Luke Skywalker
- Attributes (Properties) – e.g. Luke Skywalker is a Jedi, Darth Vader is a Sith Lord
KGs show how concepts are interconnected, enabling deeper understanding through context. Built on enterprise and domain-specific data (e.g. healthcare, finance, legal, defense, manufacturing), they give AI agents structured, contextual knowledge – essential for precision in technical, knowledge-intensive fields.
(and yes, we deliberately threw in some Star Wars to make sure you’re paying attention. AI agents emulate humans in many ways, such as the unfortunate “lost-in-the-middle”)
An ontology is the blueprint or rulebook of a knowledge graph. It defines:
- Valid entities (e.g. Yoda exists in Star Wars, not Harry Potter)
- Allowed properties (e.g. affiliation = Jedi or Sith Lord, not Gryffindor)
- Logical relationships (e.g. A Jedi owns a Lightsaber, not the reverse)
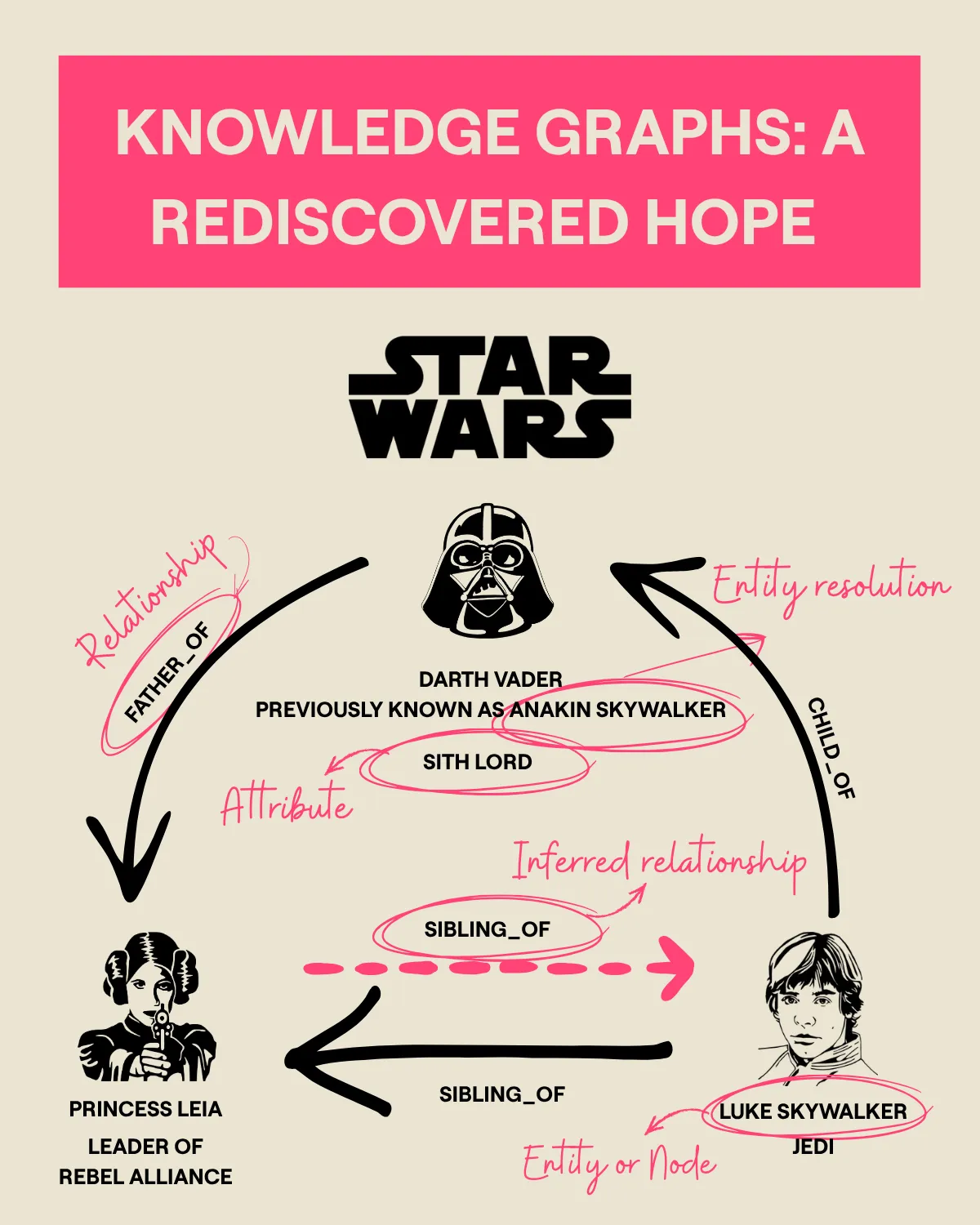
Ontologies also unify fragmented enterprise data by standardising definitions across teams (e.g. Customer_ID vs User_ID) ensuring consistent business logic and reusable domain knowledge. Beyond explicit facts, ontologies enable logical inference – understanding what can be derived from data through hierarchical, transitive, and symmetric reasoning (e.g. if Luke is Leia’s sibling, Leia is Luke’s sibling). This reasoning power makes ontology-driven KGs invaluable for AI agents, providing both structure and the foundation for symbolic reasoning, in a way that complements Retrieval Augmented Generation (RAG) and other retrieval strategies.
Standard RAG and semantic search retrieve information that sounds similar to a query but can’t reason or connect related facts – they treat knowledge as isolated text chunks. Vector embeddings capture meaning, not structure, so standard RAG struggles with multi-step (“multi-hop”) reasoning and can’t link scattered or relational data. Meanwhile, relational databases store data in rigid tables where relationships are only implied through joins. As relationships grow deeper and more complex, queries become slow, costly, and hard to manage. KGs solve both problems by storing entities, relationships, and attributes as a connected network of meaning. They make relationships first-class citizens, enabling natural traversal, multi-hop reasoning, and unified understanding across silos. This leads to AI agents that are faster, more accurate, explainable, and capable of true reasoning over interconnected knowledge.
The Startups in This Space
Section titled “The Startups in This Space”Building and maintaining KGs and ontologies is difficult, time-consuming, and expensive because they require continuous curation, schema updates, and alignment with evolving business data. However, Large Language Models (LLMs) make this process far easier by automatically reading data, extracting entities, classifying them, and suggesting ontology updates. LLMs effectively turn what was once a manual, iterative rebuild into an adaptive, scalable process – thus creating a virtuous cycle where LLMs improve KGs, and high-quality KGs in turn enhance LLM performance.
That’s why a new breed of startups have emerged, to leverage LLMs and apply them to making KGs and ontologies much more accessible. Startups in this space include Cognee, Stardog, Parsewise, Clarifeye, DataLinks, Prometheux and Blue Morpho. They extract, clean and structure data, create ontologies and KGs, and give enterprises the means to maintain them easily – all in a bid to make AI agents accurate and reliable.

Observations
Section titled “Observations”It goes without saying that the KGs and ontologies need to be high performance (low latency, high accuracy, high throughput, easily scalable and extensible so that new knowledge is easily incorporated). Besides this, we highlight three observations on approaches startups in this space are taking.
Verticalisation Vs Horizontalisation
Section titled “Verticalisation Vs Horizontalisation”We’ve seen startups taking a horizontal approach (e.g. Blue Morpho, Cognee, Parsewise, Stardog, Prometheux, DataLinks, Clarifeye) catering to a variety of industries such as healthcare, finance, legal, defence, and others taking a verticalised approach (e.g. WhyHow.AI in legal, RoeAI in risk and compliance, and Cognyx in manufacturing). Even amongst those who take a verticalised approach, WhyHow and Roe started horizontally and pivoted to a specific vertical, while Cognyx began with a specific problem (“reinventing hardware engineering”) and decided that knowledge graphs were the best way to solve it.
We believe there is a case to be made for verticalisation, partly because different use cases and different industries would likely need different graph structures. The use cases are complex, underpinned by different data structures, retrieval strategies and data processing strategies. They also often require custom approaches (which feeds into our point later on having a Forward Deployment strategy). It’s also easier (from a GTM perspective) to build a beachhead in one vertical and use the success there as a springboard to another vertical. That said, horizontal strategies succeed where players have significantly automated the deployment process (leading to shorter implementation times) and the GTM is vertical/use case oriented.
Human-in-the-loop Approach Bringing in Domain Expertise
Section titled “Human-in-the-loop Approach Bringing in Domain Expertise”Despite advancements with LLMs significantly simplifying knowledge graph and ontology creation as well as maintenance, we’re not keen on complete automation of the process. We think a human-in-the-loop approach is necessary for not only bringing in domain experts’ unique perspectives, real-world knowledge and preferences, but also in lowering costs and hastening time-to-value. Instead of hiring specialised teams of knowledge engineers or ontologists to work for years, you could instead harness the capabilities of the domain experts within your organisation who would be working with the outputs of the KG in their day-to-day operations anyway.
The question then becomes: what does the ideal balance of automation and human intervention look like? We think this involves two parts: (a) the actual workflows managed by LLMs and humans; and (b) expectation management around the workflows managed by LLMs.
For (a) we think LLMs can work on data at scale, and clean them down to levels where a human can take over the process, review and edit. More importantly, this process should be easy for a human e.g. a domain expert can build ontologies in direct conversations with LLMs.
As for point (b) on expectation management, we couldn’t illustrate it better than Chia Jeng Yang, CEO and co-founder of WhyHow.AI did in a blog post:
Forward Deployment Strategies and Implementation Automation
Section titled “Forward Deployment Strategies and Implementation Automation”As we discussed earlier, knowledge graph and ontology construction varies by use case and industry. Because the problems being solved are so unique and complex, they can’t always be solved with a simple “off-the-shelf” product – a lot of customisation goes into contextualising the initial data structure and reasoning framework. That’s why you need a Forward Deployed Engineer (FDE) – a software engineer who works directly with customers, often embedded within their teams, to solve complex, real-world problems. So it’s a hybrid role where an FDE is a software developer, a consultant and a product manager, all rolled into one. That said, we’re seeing significant automation efforts from startups such as Stardog and Cognee who are reducing the implementation time – e.g. Stardog’s Designer ontologist-in-a-box.

In Memory of… Forgetful, Hallucinating Agents?
Section titled “In Memory of… Forgetful, Hallucinating Agents?”While it seems trifle morbid to be ending things with a tombstone, it does seem fitting considering we’ve reached the end of our research report. We’re delighted to see the progress being made in the fields of context, memory, learning, accuracy and reliability of AI agents – everything from Google’s latest research on Nested Learning (to overcome issues around catastrophic forgetting, where learning new tasks sacrifices proficiency on old tasks) to Thinking Machines Lab’s work on Defeating Nondeterminism in LLM Inference. And of course, all the great work that startups mentioned in this article are doing. In the next part of our research series on Agentic Enablers, we’ll focus on startups who are making AI agents robust against unintended failure modes and malicious attacks, as well as managing authentication and authorisation for agents – see the link here.
If you’ve already forgotten how our article began, we reiterate what Steven Wright said, “Right now I’m having amnesia and déjà vu at the same time. I think I’ve forgotten this before.” If you’re a startup founder building in this space, and rather catastrophically we’ve forgotten to include your startup in our market map – please reach out to Advika or Sevi. We love to continuously learn (much like the ideal AI agent) and would be delighted to chat.