maartengrootendorst.com - A Visual Guide to LLM Agents
Exploring the main components of Single- and Multi-Agents
Section titled “Exploring the main components of Single- and Multi-Agents”Translations - Korean - Chinese - Vietnamese - French
Section titled “Translations - Korean - Chinese - Vietnamese - French”LLM Agents are becoming widespread, seemingly taking over the “regular” conversational LLM we are familiar with. These incredible capabilities are not easily created and require many components working in tandem.
With over 60 custom visuals in this post, you will explore the field of LLM Agents, their main components, and explore Multi-Agent frameworks.
👈 click on the stack of lines on the left to see a Table of Contents (ToC)
What Are LLM Agents?
Section titled “What Are LLM Agents?”To understand what LLM Agents are, let us first explore the basic capabilities of an LLM. Traditionally, an LLM does nothing more than next-token prediction.
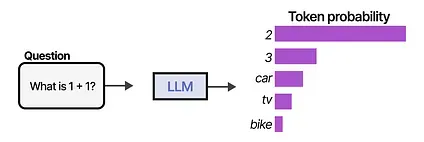
By sampling many tokens in a row, we can mimic conversations and use the LLM to give more extensive answers to our queries.

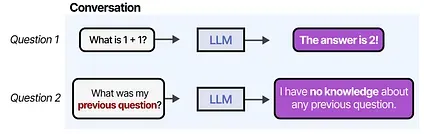
However, when we continue the “conversation”, any given LLM will showcase one of its main disadvantages. It does not remember conversations!
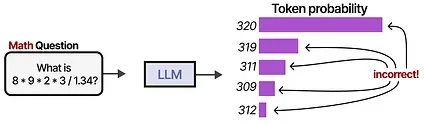
There are many other tasks that LLMs often fail at, including basic math like multiplication and division:
Does this mean LLMs are horrible? Definitely not! There is no need for LLMs to be capable of everything as we can compensate for their disadvantage through external tools, memory, and retrieval systems.
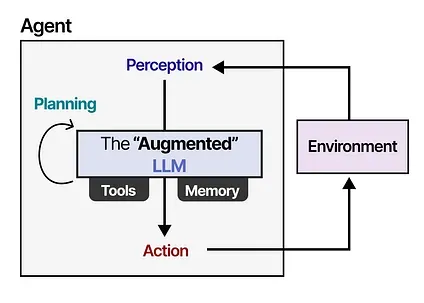
Through external systems, the capabilities of the LLM can be enhanced. Anthropic calls this “The Augmented LLM”.
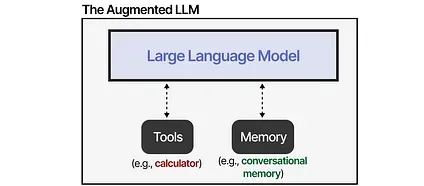
For instance, when faced with a math question, the LLM may decide to use the appropriate tool (a calculator).
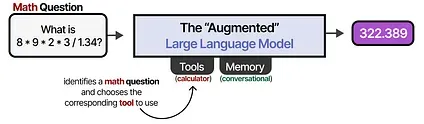
So is this “Augmented LLM” then an Agent? No, and maybe a bit yes…
Let’s start with a definition of Agents:1
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators.
— Russell & Norvig, AI: A Modern Approach (2016)
Agents interact with their environment and typically consist of several important components:
- Environments — The world the agent interacts with
- Sensors — Used to observe the environment
- Actuators — Tools used to interact with the environment
- Effectors — The “brain” or rules deciding how to go from observations to actions
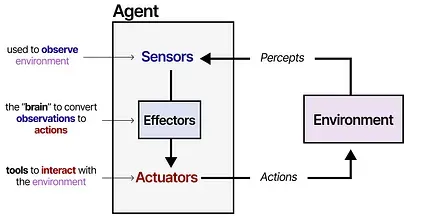
This framework is used for all kinds of agents that interact with all kinds of environments, like robots interacting with their physical environment or AI agents interacting with software.
We can generalize this framework a bit to make it suitable for the “Augmented LLM” instead.
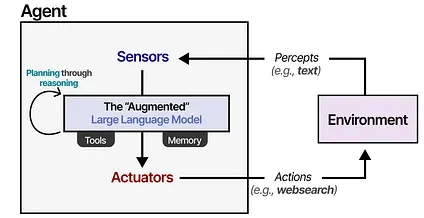
Using the “Augmented” LLM, the Agent can observe the environment through textual input (as LLMs are generally textual models) and perform certain actions through its use of tools (like searching the web).
To select which actions to take, the LLM Agent has a vital component: its ability to plan. For this, LLMs need to be able to “reason” and “think” through methods like chain-of-thought.
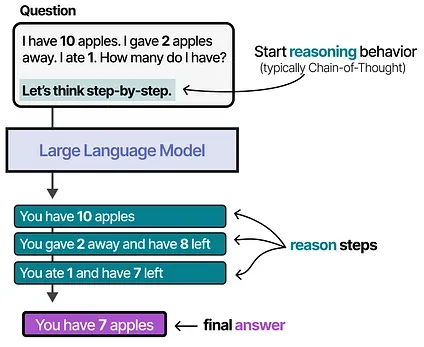
For more information about reasoning, check out The Visual Guide to Reasoning LLMs
Using this reasoning behavior, LLM Agents will plan out the necessary actions to take.
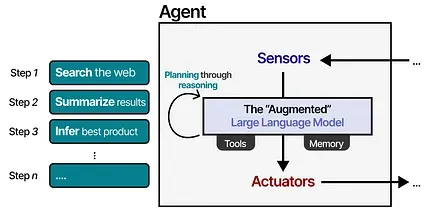
This planning behavior allows the Agent to understand the situation (LLM), plan next steps (planning), take actions (tools), and keep track of the taken actions (memory).
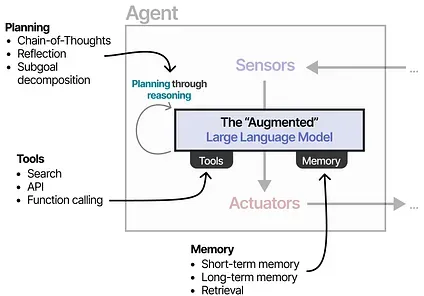
Depending on the system, you can LLM Agents with varying degrees of autonomy.
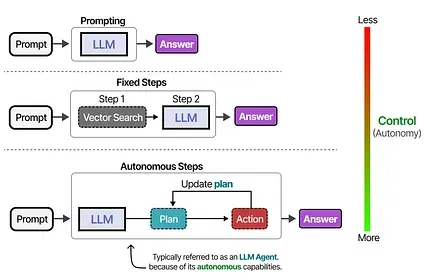
Depending on who you ask, a system is more “agentic” the more the LLM decides how the system can behave.
In the next sections, we will go through various methods of autonomous behavior through the LLM Agent’s three main components: Memory, Tools, and Planning.
Memory
Section titled “Memory”LLMs are forgetful systems, or more accurately, do not perform any memorization at all when interacting with them.
For instance, when you ask an LLM a question and then follow it up with another question, it will not remember the former.
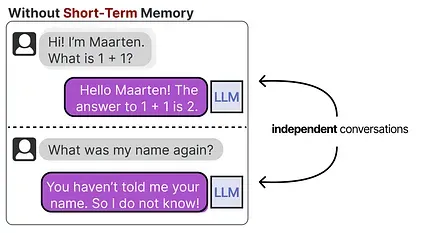
We typically refer to this as short-term memory, also called working memory, which functions as a buffer for the (near-) immediate context. This includes recent actions the LLM Agent has taken.
However, the LLM Agent also needs to keep track of potentially dozens of steps, not only the most recent actions.
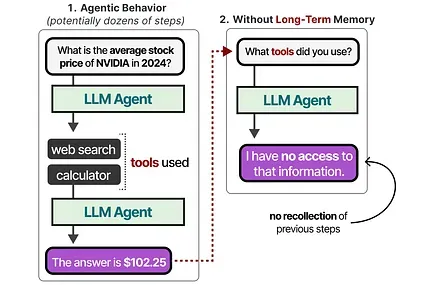
This is referred to as long-term memory as the LLM Agent could theoretically take dozens or even hundreds of steps that need to be memorized.
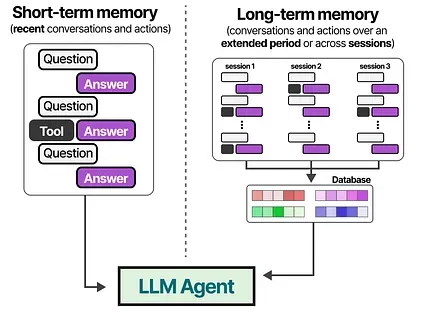
Let’s explore several tricks for giving these models memory.
Short-Term Memory
Section titled “Short-Term Memory”The most straightforward method for enabling short-term memory is to use the model’s context window, which is essentially the number of tokens an LLM can process.
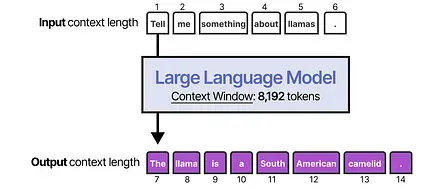
The context window tends to be at least 8192 tokens and sometimes can scale up to hundreds of thousands of tokens!
A large context window can be used to track the full conversation history as part of the input prompt.
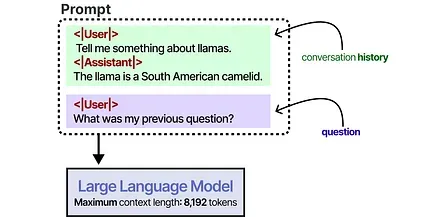
This works as long as the conversation history fits within the LLM’s context window and is a nice way of mimicking memory. However, instead of actually memorizing a conversation, we essentially “tell” the LLM what that conversation was.
For models with a smaller context window, or when the conversation history is large, we can instead use another LLM to summarize the conversations that happened thus far.
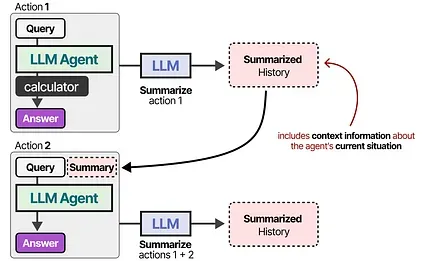
By continuously summarizing conversations, we can keep the size of this conversation small. It will reduce the number of tokens while keeping track of only the most vital information.
Long-term Memory
Section titled “Long-term Memory”Long-term memory in LLM Agents includes the agent’s past action space that needs to be retained over an extended period.
A common technique to enable long-term memory is to store all previous interactions, actions, and conversations in an external vector database.
To build such a database, conversations are first embedded into numerical representations that capture their meaning.
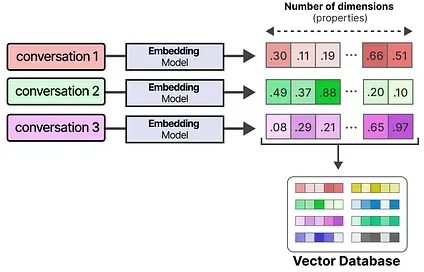
After building the database, we can embed any given prompt and find the most relevant information in the vector database by comparing the prompt embedding with the database embeddings.
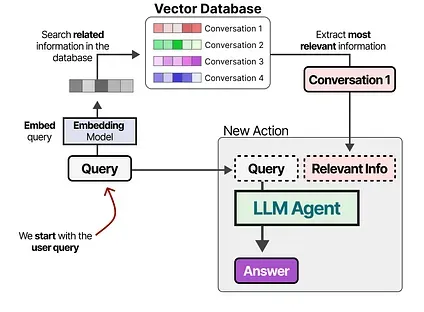
This method is often referred to as Retrieval-Augmented Generation (RAG).
Long-term memory can also involve retaining information from different sessions. For instance, you might want an LLM Agent to remember any research it has done in previous sessions.
Different types of information can also be related to different types of memory to be stored. In psychology, there are numerous types of memory to differentiate, but the Cognitive Architectures for Language Agents paper coupled four of them to LLM Agents.2

This differentiation helps in building agentic frameworks. Semantic memory (facts about the world) might be stored in a different database than working memory (current and recent circumstances).
Tools allow a given LLM to either interact with an external environment (such as databases) or use external applications (such as custom code to run).

Tools generally have two use cases: fetching data to retrieve up-to-date information and taking action like setting a meeting or ordering food.
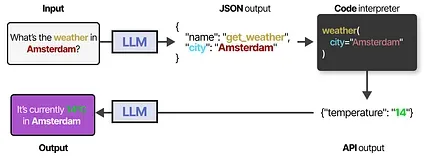
To actually use a tool, the LLM has to generate text that fits with the API of the given tool. We tend to expect strings that can be formatted to JSON so that it can easily be fed to a code interpreter.
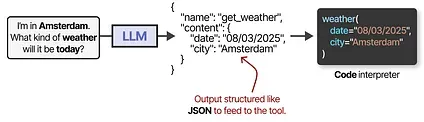
Note that this is not limited to JSON, we can also call the tool in code itself!
You can also generate custom functions that the LLM can use, like a basic multiplication function. This is often referred to as function calling.
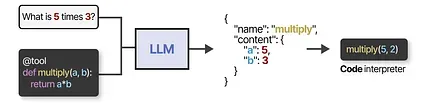
Some LLMs can use any tools if they are prompted correctly and extensively. Tool-use is something that most current LLMs are capable of.
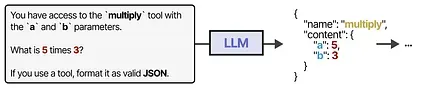
A more stable method for accessing tools is by fine-tuning the LLM (more on that later!).
Tools can either be used in a given order if the agentic framework is fixed…
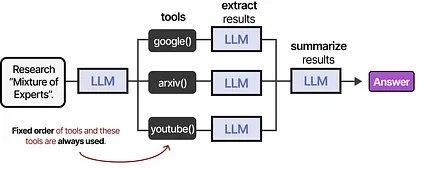
…or the LLM can autonomously choose which tool to use and when. LLM Agents, like the above image, are essentially sequences of LLM calls (but with autonomous selection of actions/tools/etc.).
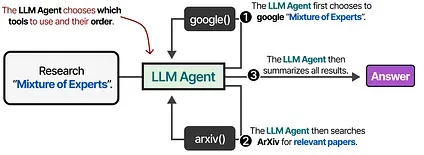
In other words, the output of intermediate steps is fed back into the LLM to continue processing.
Toolformer
Section titled “Toolformer”Tool use is a powerful technique for strengthening LLMs’ capabilities and compensating for their disadvantages. As such, research efforts on tool use and learning have seen a rapid surge in the last few years.
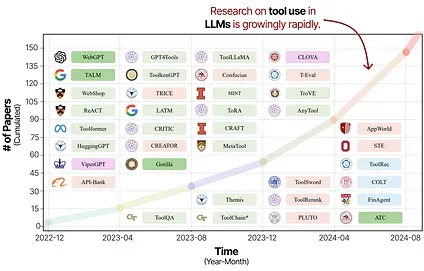
Annotated and cropped picture of the “ Tool Learning with Large Language Models: A Survey ” paper. With an increasing focus on tool use, (Agentic) LLMs are expected to become more powerful.
Much of this research involves not only prompting LLMs for tool use but training them specifically for tool use instead.
One of the first techniques to do so is called Toolformer, a model trained to decide which APIs to call and how.3
It does so by using the [ and ] tokens to indicate the start and end of calling a tool. When given a prompt, for example “ What is 5 times 3?”, it starts generating tokens until it reaches the [ token.

After that, it generates tokens until it reaches the → token which indicates that the LLM stops generating tokens.

Then, the tool will be called, and the output will be added to the tokens generated thus far.
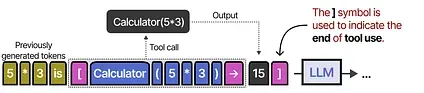
The ] symbol indicates that the LLM can now continue generating if necessary.
Toolformer creates this behavior by carefully generating a dataset with many tool uses the model can train on. For each tool, a few-shot prompt is manually created and used to sample outputs that use these tools.
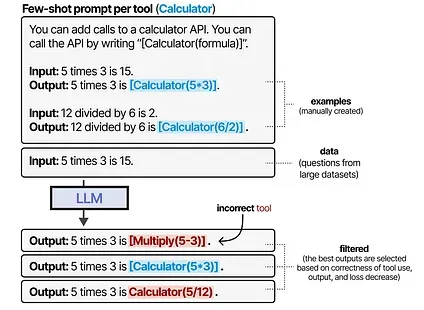
The outputs are filtered based on correctness of the tool use, output, and loss decrease. The resulting dataset is used to train an LLM to adhere to this format of tool use.
Since the release of Toolformer, there have been many exciting techniques such as LLMs that can use thousands of tools (ToolLLM 4) or LLMs that can easily retrieve the most relevant tools (Gorilla 5).
Either way, most current LLMs (beginning of 2025) have been trained to call tools easily through JSON generation (as we saw before).
Model Context Protocol (MCP)
Section titled “Model Context Protocol (MCP)”Tools are an important component of Agentic frameworks, allowing LLMs to interact with the world and extend their capabilities. However, enabling tool use when you have many different API becomes troublesome as any tool needs to be:
- Manually tracked and fed to the LLM
- Manually described (including its expected JSON schema)
- Manually updated whenever its API changes
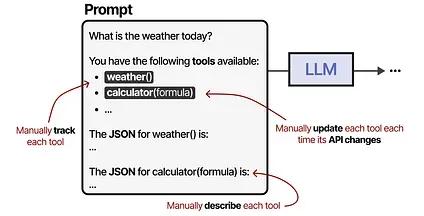
To make tools easier to implement for any given Agentic framework, Anthropic developed the Model Context Protocol (MCP).6 MCP standardizes API access for services like weather apps and GitHub.
It consists of three components:
- MCP Host — LLM application (such as Cursor) that manages connections
- MCP Client — Maintains 1:1 connections with MCP servers
- MCP Server — Provides context, tools, and capabilities to the LLMs
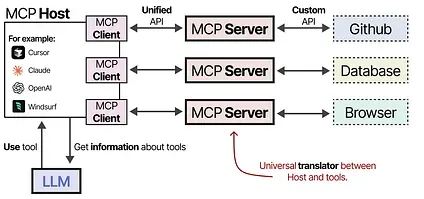
For example, let’s assume you want a given LLM application to summarize the 5 latest commits from your repository.
The MCP Host (together with the client) would first call the MCP Server to ask which tools are available.
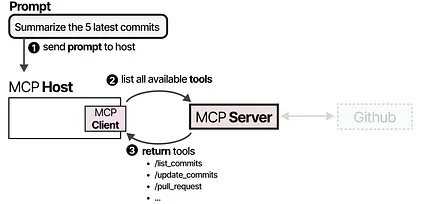
The LLM receives the information and may choose to use a tool. It sends a request to the MCP Server via the Host, then receives the results, including the tool used.
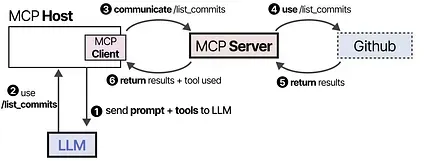
Finally, the LLM receives the results and can parse an answer to the user.
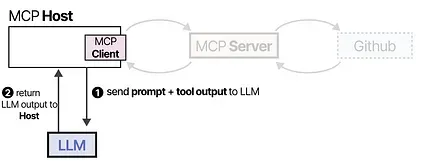
This framework makes creating tools easier by connecting to MCP Servers that any LLM application can use. So when you create an MCP Server to interact with Github, any LLM application that supports MCP can use it.
Planning
Section titled “Planning”Tool use allows an LLM to increase its capabilities. They are typically called using JSON-like requests.
But how does the LLM, in an agentic system, decide which tool to use and when?
This is where planning comes in. Planning in LLM Agents involves breaking a given task up into actionable steps.
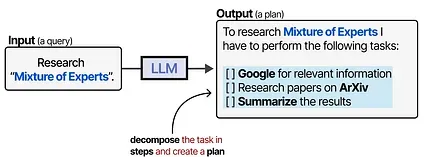
This plan allows the model to iteratively reflect on past behavior and update the current plan if necessary.

I love it when a plan comes together!
To enable planning in LLM Agents, let’s first look at the foundation of this technique, namely reasoning.
Reasoning
Section titled “Reasoning”Planning actionable steps requires complex reasoning behavior. As such, the LLM must be able to showcase this behavior before taking the next step in planning out the task.
“Reasoning” LLMs are those that tend to “think” before answering a question.
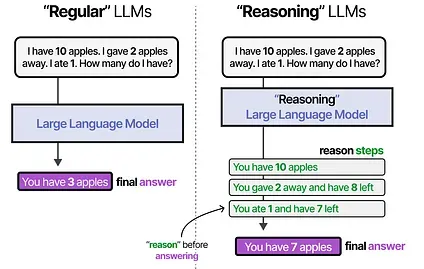
This reasoning behavior can be enabled by roughly two choices: fine-tuning the LLM or specific prompt engineering.
With prompt engineering, we can create examples of the reasoning process that the LLM should follow. Providing examples (also called few-shot prompting 7) is a great method for steering the LLM’s behavior.
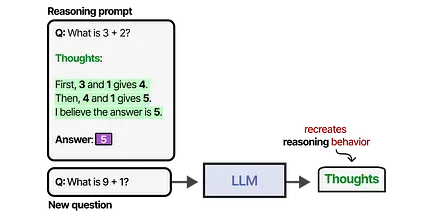
This methodology of providing examples of thought processes is called Chain-of-Thought and enables more complex reasoning behavior.8
Chain-of-thought can also be enabled without any examples (zero-shot prompting) by simply stating “Let’s think step-by-step”.9

When training an LLM, we can either give it a sufficient amount of datasets that include thought-like examples or the LLM can discover its own thinking process.
A great example is DeepSeek-R1 where rewards are used to guide the usage of thinking processes.
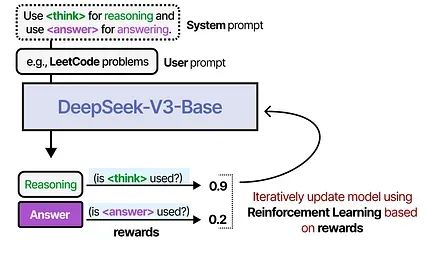
For more information about Reasoning LLMs, see my visual guide.
Reasoning and Acting
Section titled “Reasoning and Acting”Enabling reasoning behavior in LLMs is great but does not necessarily make it capable of planning actionable steps.
The techniques we focused on thus far either showcase reasoning behavior or interact with the environment through tools.

Chain-of-Thought, for instance, is focused purely on reasoning.
One of the first techniques to combine both processes is called ReAct (Reason and Act).10
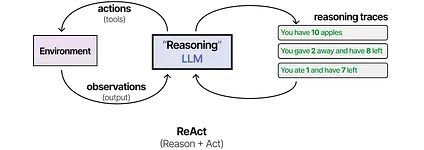
ReAct does so through careful prompt engineering. The ReAct prompt describes three steps:
- Thought - A reasoning step about the current situation
- Action - A set of actions to execute (e.g., tools)
- Observation - A reasoning step about the result of the action
The prompt itself is then quite straightforward.

The LLM uses this prompt (which can be used as a system prompt) to steer its behaviors to work in cycles of thoughts, actions, and observations.
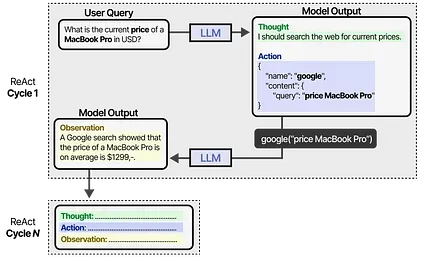
It continues this behavior until an action specifies to return the result. By iterating over thoughts and observations, the LLM can plan out actions, observe its output, and adjust accordingly.
As such, this framework enables LLMs to demonstrate more autonomous agentic behavior compared to Agents with predefined and fixed steps.
Reflecting
Section titled “Reflecting”Nobody, not even LLMs with ReAct, will perform every task perfectly. Failing is part of the process as long as you can reflect on that process.
This process is missing from ReAct and is where Reflexion comes in. Reflexion is a technique that uses verbal reinforcement to help agents learn from prior failures.11
The method assumes three LLM roles:
- Actor — Chooses and executes actions based on state observations. We can use methods like Chain-of-Thought or ReAct.
- Evaluator — Scores the outputs produced by the Actor.
- Self-reflection — Reflects on the action taken by the Actor and scores generated by the Evaluator.
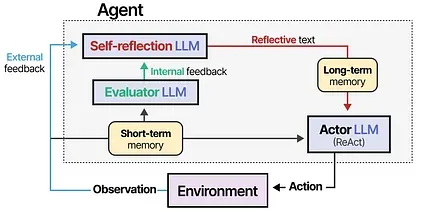
Memory modules are added to track actions (short-term) and self-reflections (long-term), helping the Agent learn from its mistakes and identify improved actions.
A similar and elegant technique is called SELF-REFINE, where actions of refining output and generating feedback are repeated.12
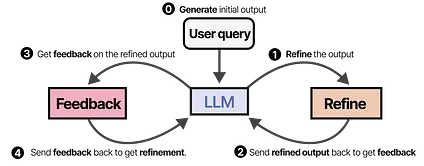
The same LLM is in charge of generating the initial output, the refined output, and feedback.

Annotated figure of the “ SELF-REFINE: Iterative Refinement with Self-Feedback ” paper.
Interestingly, this self-reflective behavior, both Reflexion and SELF-REFINE, closely resembles that of reinforcement learning where a reward is given based on the quality of the output.
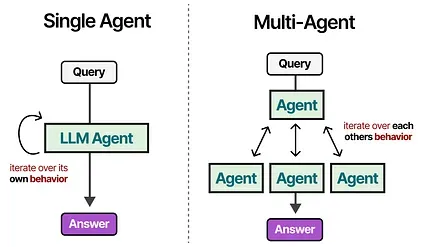
Multi-Agent Collaboration
Section titled “Multi-Agent Collaboration”The single Agent we explored has several issues: too many tools may complicate selection, context becomes too complex, and the task may require specialization.
Instead, we can look towards Multi-Agents, frameworks where multiple agents (each with access to tools, memory, and planning) are interacting with each other and their environments:
These Multi-Agent systems usually consist of specialized Agents, each equipped with their own toolset and overseen by a supervisor. The supervisor manages communication between Agents and can assign specific tasks to the specialized Agents.
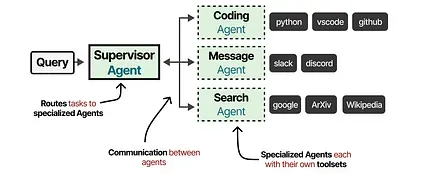
Each Agent might have different types of tools available, but there might also be different memory systems.
In practice, there are dozens of Multi-Agent architectures with two components at their core:
- Agent Initialization — How are individual (specialized) Agents created?
- Agent Orchestration — How are all Agents coordinated?
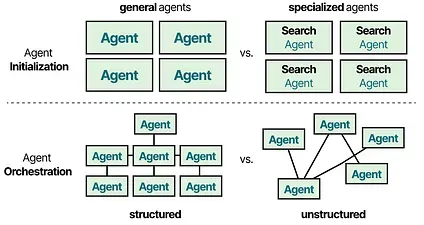
Let’s explore various interesting Multi-Agent frameworks and highlight how these components are implemented.
Interactive Simulacra of Human Behavior
Section titled “Interactive Simulacra of Human Behavior”Arguably one of the most influential, and frankly incredibly cool, Multi-Agent papers is called “ Generative Agents: Interactive Simulacra of Human Behavior ”.13
In this paper, they created computational software agents that simulate believable human behavior, which they call Generative Agents.

The profile each Generative Agent is given makes them behave in unique ways and helps create more interesting and dynamic behavior.
Each Agent is initialized with three modules (memory, planning, and reflection) very much like the core components that we have seen previously with ReAct and Reflexion.
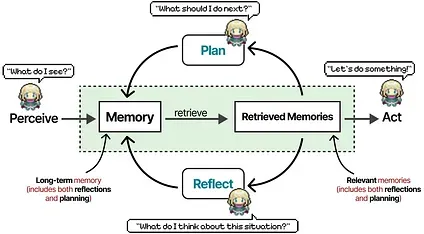
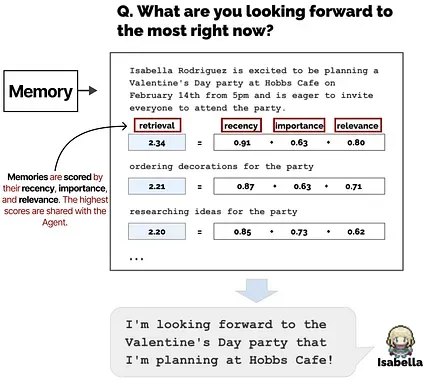
The Memory module is one of the most vital components in this framework. It stores both the planning and reflection behaviors, as well as all events thus far.
For any given next step or question, memories are retrieved and scored on their recency, importance, and relevance. The highest scoring memories are shared with the Agent.
Annoted figure of the Generative Agents: Interactive Simulacra of Human Behavior paper.
Together, they allow for Agents to freely go about their behavior and interact with one another. As such, there is very little Agent orchestration as they do not have specific goals to work to.
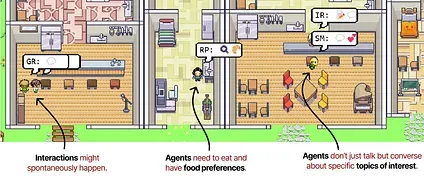
Annotated image from the interactive demo.
There are too many amazing snippets of information in this paper, but I want to highlight their evaluation metric.14
Their evaluation involved the believability of the Agent’s behaviors as the main metric, with human evaluators scoring them.
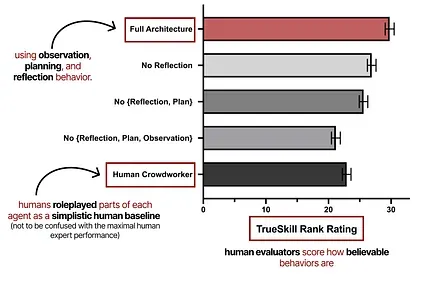
Annotated figure of the Generative Agents: Interactive Simulacra of Human Behavior paper.
It showcases how important observation, planning, and reflection are together in the performance of these Generative Agents. As explored before, planning is not complete without reflective behavior.
Modular Frameworks
Section titled “Modular Frameworks”Whatever framework you choose for creating Multi-Agent systems, they are generally composed of several ingredients, including its profile, perception of the environment, memory, planning, and available actions.15 16
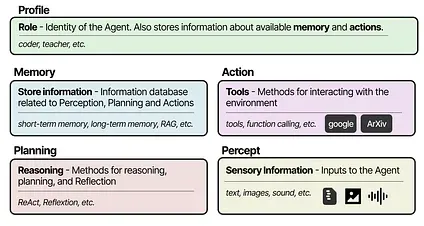
Popular frameworks for implementing these components are AutoGen 17, MetaGPT 18, and CAMEL 19. However, each framework approaches communication between each Agent a bit differently.
With CAMEL, for instance, the user first creates its question and defines AI User and AI Assistant roles. The AI user role represents the human user and will guide the process.

After that, the AI User and AI Assistant will collaborate on resolving the query by interacting with each other.
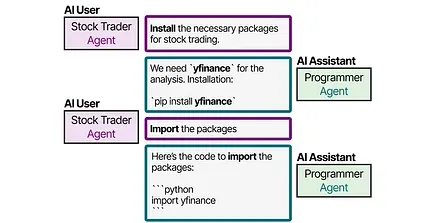
This role-playing methodology enables collaborative communication between agents.
AutoGen and MetaGPT have different methods of communication, but it all boils down to this collaborative nature of communication. Agents have opportunities to engage and talk with one another to update their current status, goals, and next steps.
In the last year, and especially the last few weeks, the growth of these frameworks has been explosive.
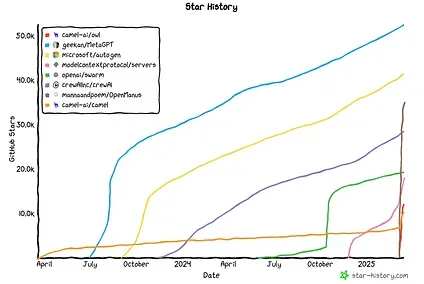
2025 is going to be a truly exciting year as these frameworks keep maturing and developing!
Conclusion
Section titled “Conclusion”This concludes our journey of LLM Agents! Hopefully, this post gives a better understanding of how LLM Agents are built.
To see more visualizations related to LLMs and to support this newsletter, check out the book I wrote on Large Language Models!

Official website of the book. You can order the book on Amazon. All code is uploaded to GitHub.
Footnotes
Section titled “Footnotes”-
Russell, S. J., & Norvig, P. (2016). Artificial intelligence: a modern approach. pearson. ↩
-
Sumers, Theodore, et al. “Cognitive architectures for language agents.” Transactions on Machine Learning Research (2023). ↩
-
Schick, Timo, et al. “Toolformer: Language models can teach themselves to use tools.” Advances in Neural Information Processing Systems 36 (2023): 68539-68551. ↩
-
Qin, Yujia, et al. “Toolllm: Facilitating large language models to master 16000+ real-world apis.” arXiv preprint arXiv:2307.16789 (2023). ↩
-
Patil, Shishir G., et al. “Gorilla: Large language model connected with massive apis.” Advances in Neural Information Processing Systems 37 (2024): 126544-126565. ↩
-
“Introducing the Model Context Protocol.” Anthropic, www.anthropic.com/news/model-context-protocol. Accessed 13 Mar. 2025. ↩
-
Mann, Ben, et al. “Language models are few-shot learners.” arXiv preprint arXiv:2005.14165 1 (2020): 3. ↩
-
Wei, Jason, et al. “Chain-of-thought prompting elicits reasoning in large language models.” Advances in neural information processing systems 35 (2022): 24824-24837. ↩
-
Kojima, Takeshi, et al. “Large language models are zero-shot reasoners.” Advances in neural information processing systems 35 (2022): 22199-22213. ↩
-
Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, and Cao, Yuan. ReAct: Synergizing Reasoning and Acting in Language Models. Retrieved from https://par.nsf.gov/biblio/10451467. International Conference on Learning Representations (ICLR). ↩
-
Shinn, Noah, et al. “Reflexion: Language agents with verbal reinforcement learning.” Advances in Neural Information Processing Systems 36 (2023): 8634-8652. ↩
-
Madaan, Aman, et al. “Self-refine: Iterative refinement with self-feedback.” Advances in Neural Information Processing Systems 36 (2023): 46534-46594. ↩
-
Park, Joon Sung, et al. “Generative agents: Interactive simulacra of human behavior.” Proceedings of the 36th annual acm symposium on user interface software and technology. 2023. ↩
-
To see a cool interactive playground of the Generative Agents, follow this link: https://reverie.herokuapp.com/arXiv_Demo/ ↩
-
Wang, Lei, et al. “A survey on large language model based autonomous agents.” Frontiers of Computer Science 18.6 (2024): 186345. ↩
-
Xi, Zhiheng, et al. “The rise and potential of large language model based agents: A survey.” Science China Information Sciences 68.2 (2025): 121101. ↩
-
Wu, Qingyun, et al. “Autogen: Enabling next-gen llm applications via multi-agent conversation.” arXiv preprint arXiv:2308.08155 (2023). ↩
-
Hong, Sirui, et al. “Metagpt: Meta programming for multi-agent collaborative framework.” arXiv preprint arXiv:2308.00352 3.4 (2023): 6. ↩
-
Li, Guohao, et al. “Camel: Communicative agents for” mind” exploration of large language model society.” Advances in Neural Information Processing Systems 36 (2023): 51991-52008. ↩