Product-Driven AI Research
- Layout the long term goal of what you hope the model / agent to be able to do.
- Ground your goals in specific user scenarios.
- For existing products, data scientists should perform rigorous experiments to draw insights and trends from user data and know the limits of the model. These insights help scope the research proposal and are transferred to the researchers who train the model.
- Then iterate: break the long term goal into viable experimental plans with clearly defined short term goals.
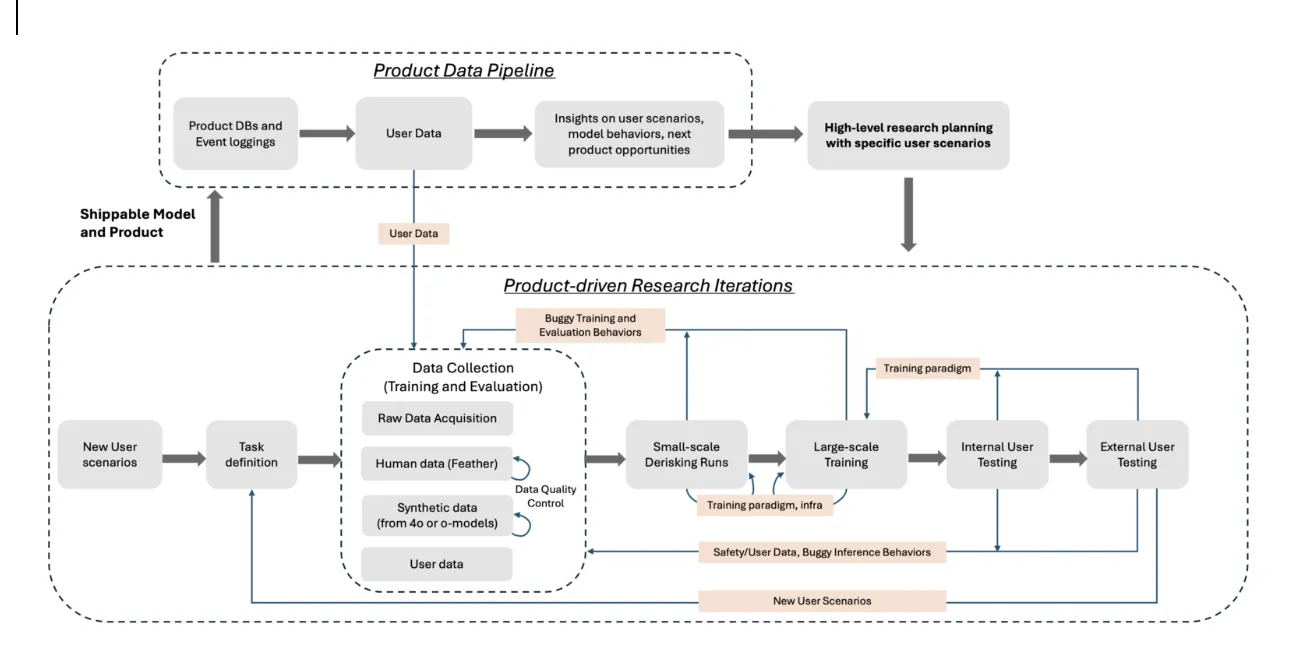
- The most important first step is to define the minimum experimental setup. This translates user scenario or product requirement into task definition, training and evaluation data, model size, and how many GPUs are needed.
- Then, back-and-forth between data and model development happens:
- Evaluation Data Construction. Based on the task definition, the researchers first constructs evaluation data either manually by themselves (can be extremely small scale, starting with 20 -30 examples), or leveraging existing open-source evaluation benchmarks.
This evaluation data is first used to evaluate existing models, e.g., 4o, or previous iterations of o-model variants. This step is essential, as it helps to evaluate the quality of the evaluation data. The ideal evaluation data should be:
- Hard enough so that it can clearly benchmark the improvement in model performance through training
- Not too hard so that it is possible to improve the model via training (e.g., if success rate of o1 is 0%, then it maybe too hard to get valuable CoTs during Berrification)
- Fits the user scenario with clear evaluation metrics (e.g., accuracy, pass rate)
If with manual creation, once the three requirements have been satisfied at small scale, the researchers arrive at a guideline, then send to Feather to scale up the data collection (E.g., in Deep Research).
In the case of SWEAgent, evaluation data is collected via a rule-based synthetic pipeline, which leverages high-quality GitHub repos that already contain rich human knowledges to extract golden input/output pairs.
As the models get stronger these days, the common practice at OAI from my observation is always start with synthetic data generation first. If hard to achieve satisfying quality, then hire human workers, or even directly reach out to experts.
- Training Data Collection. Following the same guideline for human data collection or synthetic data creation process, it can be scaled up to collect more data for training. Usually, they start with ~0.5K for evaluation, and 5 - 10x bigger for training data collection for small-scale experiments on strawberry models. For human data collection, the researchers work with the human data team to monitor the quality of the data and iterate on the guidelines. For synthetic data generation, it seeds on high-quality subsets from raw data acquisition (e.g., GitHub Repos for SWEAgent, arXiv papers for o1-mini/o3-mini). The dataset owners (usually are the researchers) would need to examine and evaluate the data quality in depth to iterate on the generation process.
- Small-scale Derisking Runs. They conduct small-scale derisk training runs, extremely early, even when data collection is half-way done, usually with a single task only. For example, in SWEAgent, early derisking runs have produced models that are only trained for Repo Function Synthesis (i.e., implementing a function in a file). The goal of small-scale derisking run is to make sure that the end-to-end training pipeline guarantees model performance improvements at a small scale for a targeted task. It can reveal problems and help them iterate on data quality, evaluation metrics, training paradigms, or even sometimes infrastructure. For example, the heavy tool usage with specific environmental requirements for coding in SWEAgent made them to invent CaaS (Container as Service), a standalone server designed to provide on-demand creation and management of containers through a simple HTTP API.
- Large-scale model training. The learnings of small-scale derisking runs are well-documented to guide the design choices of large-scale model training. At this stage, they merge all relevant tasks and the associated data together for model training. It also goes through derisking runs, to make sure that the training behavior remain healthy in terms of both model performance on all tasks and infrastructure. For example, stress on infrastructure during early large-scale runs of 01 has led to improvements like Peashooter.
- Internal user testing. Intermediate checkpoints of a steady large-scale model training will be hosted internally for people to play with and share feedback. This is usually when product prototypes happen. In SWEAgent, they first build a prototype with orchestration model sitting locally on the user’s laptop and onboarded < 10 engineers/researchers internally. This direct user-researcher feedback loop allows them to iterate quickly to improve the user experience from the modeling side, which can then guide the researchers to fix the training data, or training paradigm (e.g., the simulated users in SWEAgent). Also, this is when safety team started to perform safety testing on the models (especially true for new models for new products), and safety-related data are being constantly added to training to fix safety bugs.
- External user testing. Once the model passes internal vibe check, they move to alpha (or alpha-alpha for SWEAgent) release to gather feedback from external users, and also can gather insights on interesting user scenarios that are not yet enabled by the current product. These insights guide the refinement of their proposal, to improve their models, and products.
Deeper Analysis in Gaps with Focus on Data Tooling Based on the observations above, we identify the iterative data generation process as a critical part that has made OAI successful in unlocking novel Al capabilities for their product, and calls for building the next-gen data tools to exponentially accelerate this process at MSFT.
For more details, please check out Jamie and I put together. FYI, this is still a work in progress and the goal is to spark the discussion.