x.com - Agent Harness is the Real Product
Everyone talks about models. Nobody talks about the scaffolding.
The companies shipping the best AI agents todayClaude Code, Cursor, Manus, Devin, SWE-Agent all converge on the same architecture: a deliberately simple loop wraps the model, a handful of primitive tools give it hands, and the scaffolding decides what information reaches the model and when.
The model is interchangeable. The harness is the product.
Here is the evidence:
Claude Opus 4.5 scores 42% on CORE-Bench with one scaffold and 78% with another.
Cursor’s lazy tool loading cuts token usage by 46.9%.
Vercel deleted 80% of their agent’s tools and watched it go from failing tasks to completing them.
Same model. Same benchmark. The only variable is the harness. And the single most underrated pattern inside these harnesses?
Progressive disclosureagents discovering context incrementally instead of drowning in everything upfront.
This article breaks down what a harness actually is, how each company builds theirs, and why progressive disclosure is the pattern that separates working agents from impressive demos.
Sources analyzed (all listed at the end).
What Is an Agent Harness?
Section titled “What Is an Agent Harness?”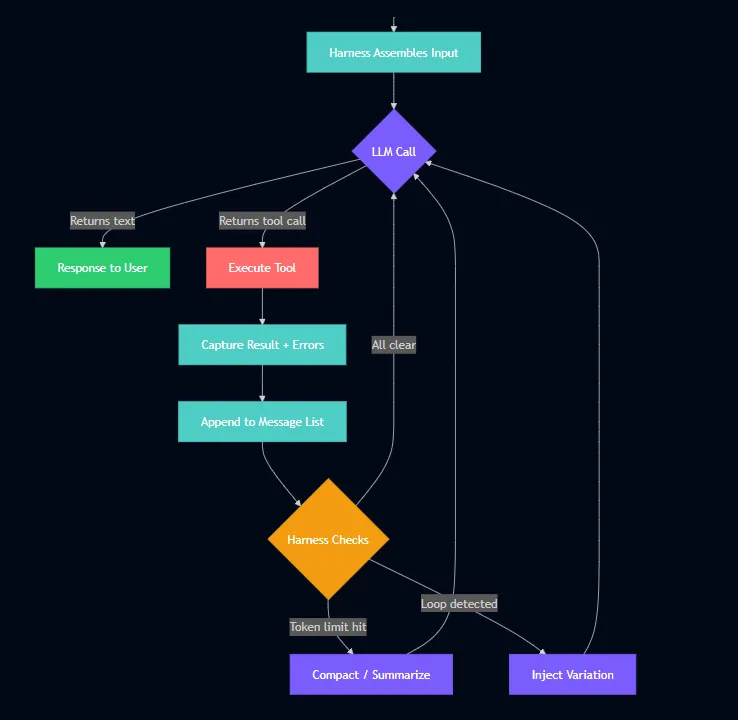
Harrison Chase (LangChain) draws the sharpest distinction: “A framework is abstractions… pretty unopinionated. Harnesses are batteries included.”
Source: LangChain “Improving Deep Agents with Harness Engineering”
An agent harness is everything around the model that makes it useful: the execution loop, tool definitions, error recovery, state management, and information flow. The model decides what to do. The harness decides what the model can see, what tools it can use, and what happens when it fails.
Every production agent converges on this core loop:
while (model returns tool calls): execute tool → capture result → append to context → call model again
That is it. The entire architecture of Claude Code, Cursor’s agent, and Manus fits inside that loop. The engineering is in what surrounds it.
How Each Company Builds Its Harness
Section titled “How Each Company Builds Its Harness”Claude Code: “The Model Controls the Loop”
Context: Claude Code’s architecture has been reverse-engineered extensively and Anthropic has published detailed posts on their harness design. The core is a single flat message list with ~18 primitive tools.
Source: Anthropic “Effective Harnesses for Long-Running Agents”
The loop. Internally codenamed nO, it is a while(tool_call) loop. No DAG orchestration, no competing agent personas. The model receives messages and tools, returns text (loop ends) or tool calls (loop continues). Anthropic explicitly calls this “the model controls the loop” rather than “code controls the model.”
The tools. ~18 primitives in four categories: command-line discovery (Bash, Glob, Grep, LS), file interaction (Read, Write, Edit, MultiEdit), web access (WebSearch, WebFetch), and orchestration (TodoWrite, Task). The philosophy is primitives over integrations. Notably, Anthropic chose regex (ripgrep) over vector databases for code search, reasoning that Claude’s code understanding enables sophisticated regex crafting without search indices.
Source: PromptLayer “Claude Code: Behind-the-Scenes of the Master Agent Loop”
The information layering. Six layers loaded at session start: organization policies, project-level CLAUDE.md, user settings, auto-learned MEMORY.md, session history, and git state. The system prompt comprises ~110+ conditional strings (~2,896 token core). A critical but underappreciated harness pattern: tool results carry injected system reminders fixed text appended after every tool execution. This achieves higher behavioral adherence than system-prompt-only instructions because it repeats with every call.
Source: Vrungta “Claude Code Architecture (Reverse Engineered)”
Error recovery. Primarily model-driven. Failed tool executions return error messages as tool results, and the model decides what to do. The TodoWrite tool serves as a “progress anchor” after errors, the model consults its TODO list to know where it was.
The insight that matters: Claude Code’s TodoWrite tool does nothing functionally. It is purely a harness-level tricka no-op tool that forces the agent to articulate and track its plan, keeping it on course over long trajectories. LangChain’s “Deep Agents” analysis calls it out explicitly.
Source: LangChain “Deep Agents”
Cursor: “Files as the Fundamental Primitive”
Context: Cursor published “Dynamic Context Discovery” (Jan 2026) and a separate post on model-specific harness tuning. Their architecture has five components: Router, LLM, 10+ tools, context retrieval, and a ReAct-style orchestrator.
Source: Cursor “Dynamic Context Discovery”
The key decision. Cursor tunes its harness specifically for every frontier model based on internal evals. Different models get different tool names, prompt instructions, and behavioral guidance. OpenAI Codex models get shell-oriented tool names like rg; Claude models get different reasoning summary formats.
Source: Cursor “Improving Cursor’s Agent for OpenAI Codex Models”
Files as context primitive. Everything in Cursor’s architecture maps to files. Why? Because files enable powerful searching (ripgrep, jq, grep, semantic search), are naturally groupable (one folder per MCP server), and are versionable. Their exact words: “Files have been a simple and powerful primitive to use, and a safer choice than yet another abstraction.”
Custom semantic search. Their embedding model is trained using agent session traces as training datawhen an agent works through a task, Cursor analyzes which files should have been retrieved earlier, then trains the embedding model to match those patterns. Result: 12.5% higher search accuracy on average and 2.6% higher code retention on large codebases (1,000+ files).
Source: Cursor “Improving Agent with Semantic Search”
Manus: “KV-Cache Above All Else”
Context: Manus has rewritten their framework five times since launch. Their average input-to-output token ratio is ~100:1. They call the iterative process “Stochastic Gradient Descent.”
Source: Manus “Context Engineering for AI Agents: Lessons from Building Manus”
Logit masking over tool removal. Manus tried adding and removing tools dynamically and rejected itany change to tool definitions near the front of the context invalidates the KV-cache for all subsequent tokens. Instead, all ~29 tools remain permanently loaded. Availability per step is controlled by constraining output token probabilities during decoding. Tool naming uses consistent prefixes (browser_*, shell_*, file_*) for group-level masking.
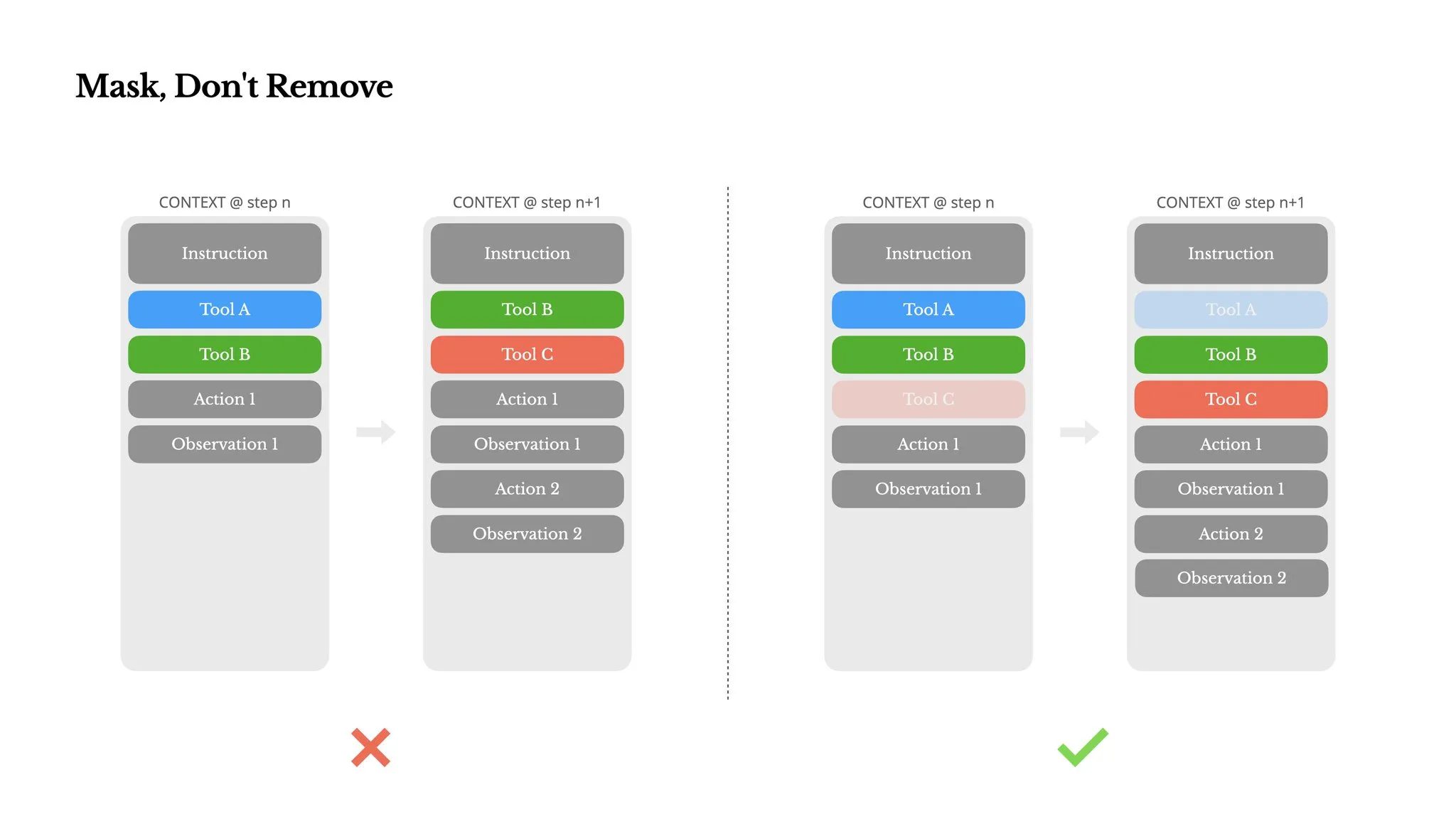
Source: Manus
Hierarchical action space. Three levels: Level 1 (~20 atomic function-call tools), Level 2 (sandbox utilities invoked via Bashgrep, ffmpeg, MCP tools via mcp-cli), Level 3 (dynamic scripts using pre-installed libraries). This keeps tool definitions out of the context window while preserving full capability.
The biggest lesson. Their biggest performance gains came from removing things; complex tool definitions replaced by shell execution, “management agents” replaced by simple handoffs. If your agent harness is getting more complex while models get better, something is wrong.
SWE-Agent: “The Agent-Computer Interface”
Context: Princeton’s SWE-Agent introduced the ACI (Agent-Computer Interface) concept at NeurIPS 2024, purpose-built interfaces designed specifically for LLM agents rather than humans.
Source: Yang et al. “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering”
Linter-gated edits. When the agent issues an edit command, a linter runs automatically. If the code isn’t syntactically correct, the edit is rejected and the agent must retry. Without this single harness-level guardrail, performance drops 3%.
Observation compression. All observations except the last 5 are collapsed to a single line each. The agent sees full detail for recent actions and summaries for older ones, a form of progressive disclosure baked into the loop.
The Others: Devin, Windsurf, Aider, Replit
Devin runs in isolated cloud VMs with a Playbook system for repeated tasks and a Knowledge Management System where feedback is codified for future reference. 67% PR merge rate, up from 34% a year ago.
Source: Cognition “Devin’s 2025 Performance Review”
Windsurf uses a two-agent architecture: a planning agent runs continuously in the background refining a long-term plan while the primary model handles short-term actions. Their “Memories” system generates observations about codebase patterns across sessions.
Aider has the most technically novel context strategy: a PageRank-based repository map built using tree-sitter. It parses code to extract definitions, builds a graph where files are nodes and dependencies are edges, applies PageRank to rank symbols by importance, and uses binary search to fit the most critical content within a token budget.
Replit Agent evolved from a single agent to a three-agent architecture (Manager, Editor, Verifier) after finding that single-agent error rates were too high. Self-healing loop: generate → execute → test with Playwright → fix → rerun.
Progressive Disclosure: The Pattern Nobody Has Named
Section titled “Progressive Disclosure: The Pattern Nobody Has Named”Progressive disclosure is borrowed from UI/UX design, originated by John Carroll at IBM Research in the 1980s, popularized by Jakob Nielsen in the 1990s. The principle: show only what is needed now, reveal complexity on demand.
The mapping to agent design is direct. Just as collapsible menus reduce cognitive load for humans, layered context loading reduces attention fragmentation for LLMs.
Source: Honra “Why AI Agents Need Progressive Disclosure, Not More Data”
How Production Systems Implement it
Section titled “How Production Systems Implement it”Claude Code’s SKILL.md pattern. Skills are stored as .claude/skills/ files and are NOT preloaded into every conversation. Unlike CLAUDE.md (loaded every session), skills load only when Claude detects relevance. The system prompt describes it as “on-demand loading” — Claude reads slide-decks.md only when creating presentations. This prevents context bloat when a project has dozens of skills.
Source: Anthropic Claude Code Best Practices
Cursor’s lazy MCP tool loading. MCP servers include many tools with long descriptions; most go unused. Cursor syncs tool descriptions to a folder structure and gives the agent only tool names as static context. Full definitions are fetched on-demand. In A/B testing: 46.9% token reduction (statistically significant).
Manus’s filesystem offloading. The agent writes to and reads from files on demand. Compression is designed to be reversible: drop a web page’s content if the URL is preserved; omit a document if its file path remains. The todo.md rewriting pattern pushes the global plan into the model’s recent attention span directly counteracting “lost in the middle.”
The quantitative case
The numbers across multiple independent sources are consistent:
Token efficiency.
- Claude-Mem documentation shows static loading injects 25,000 tokens at 0.8% efficiency (one relevant observation in noise). Progressive disclosure: 955 tokens at 100% efficiency. ~26x improvement.
- Cursor’s lazy loading: 46.9% reduction.
- Vercel’s case study: removing 80% of tools dropped tokens from 145,463 to 67,483, steps from 100 to 19, latency from 724 to 141 seconds and the agent went from failing to succeeding.
Source: Phil Schmid “Context Engineering for AI Agents: Part 2”
The scaffold matters more than the model.
- CORE-Bench: Claude Opus 4.5 scored 42% with one scaffold, 78% with another.
- Sonnet 4: 33% vs 47%. Sonnet 4.5: 44% vs 62%.
- LangChain’s deepagents-cli went from 52.8% to 66.5% on TerminalBench 2.0 (13.7 points) by changing only the harness.
Source: LangChain “Improving Deep Agents with Harness Engineering”
Why harnesses need this. Liu et al. (TACL 2024) demonstrated that LLM performance follows a U-shaped curvehighest when relevant information is at the beginning or end of the input, degraded in the middle. Even long-context models. This is why the harness matters: progressive disclosure keeps inputs small (less curve distortion) and places freshly-retrieved information at the end (the high-attention zone).
Source: Liu et al. “Lost in the Middle: How Language Models Use Long Contexts” (TACL 2024)
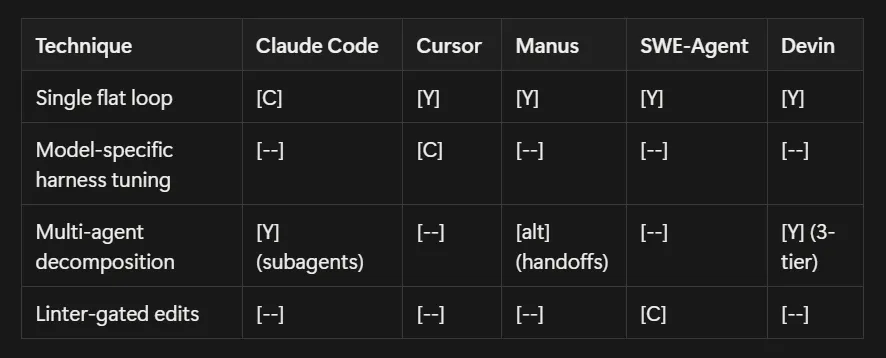
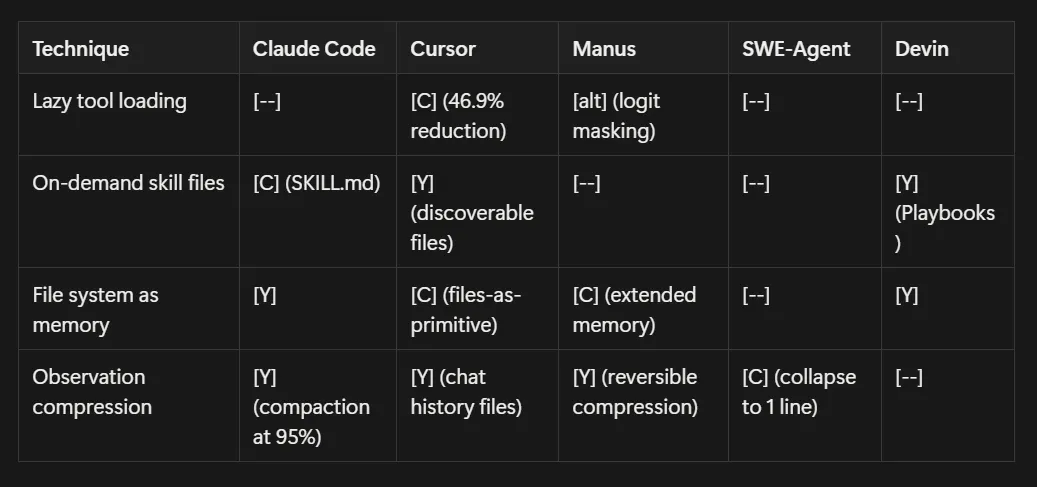
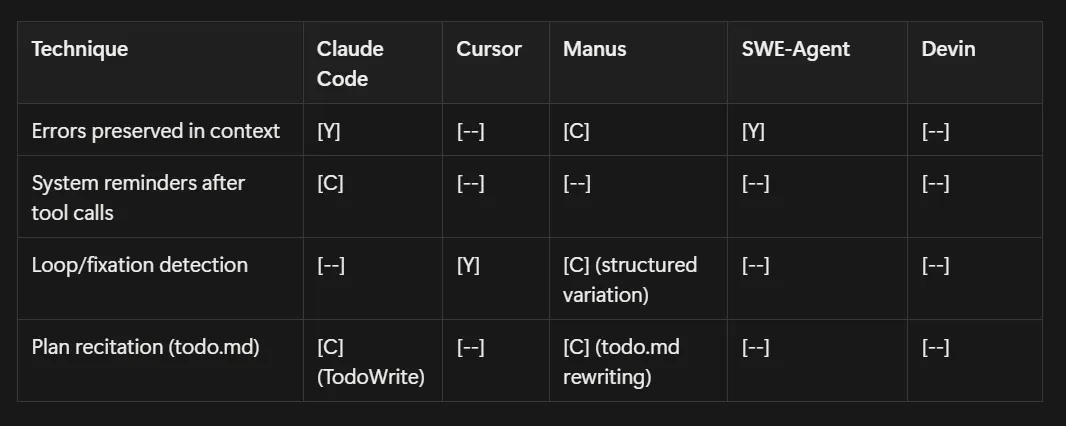
The Technique Matrix
Section titled “The Technique Matrix”Quick-reference mapping harness techniques to agent systems based on public documentation.
Legend: [C] = Core differentiator [Y] = Uses/advocates [—] = Not discussed publicly [alt] = Different approach
Loop Architecture:
Progressive Disclosure:
Error Handling & Robustness:
Where The Industry Agrees (and Where It Doesn’t)
Section titled “Where The Industry Agrees (and Where It Doesn’t)”Near-consensus: The single flat loop wins over complex orchestration. File system as extended memory. Errors preserved, not cleaned. Fake planning tools (TodoWrite, todo.md) for coherence. Primitives (bash, grep, filesystem) over custom integrations.
Active disagreement: How to handle tool overload. Manus uses logit masking (all tools loaded, constrain outputs). Cursor uses lazy loading (load tool definitions on demand). Opposite strategies. Both work. The right answer might depend on your token economics.
Active disagreement: How much should the harness manage for the model? Google’s bet is “give the model everything, let it figure it out” (2M token windows). Everyone else builds harnesses that actively filter and stage information. Research still shows 15-47% performance drops as input grows. The harness-heavy approach is winning in practice.
Unsolved: How to evaluate harness quality. Cursor’s 46.9% token reduction is one of very few published numbers. No standard benchmarks exist for comparing harness designs head-to-head. When to share sub-agent state vs isolate it is still purely empirical.
The pattern worth noting: The teams shipping the best agents keep simplifying. Manus: five rewrites, each one removed things. Anthropic designs Claude Code’s scaffold to shrink as models improve. Replit went from one agent to three but each individual agent got simpler. Over-engineering is the default failure mode.
What This Means If You Are Building Agents
Section titled “What This Means If You Are Building Agents”Three things this research makes clear:
- Spend your engineering cycles on the harness, not on model shopping.
- Progressive disclosure is not optional, it is architectural.
- Plan for your harness to get simpler, not more complex.
Dex Horthy (creator of the “12 Factor Agents” methodology) puts the threshold at 40% of the model’s input capacity: push past that and you enter what he calls the “dumb zone” - signal-to-noise degrades, attention fragments, and agents start making mistakes that look like reasoning failures but are actually information overload from a poorly designed harness.
Source: Horthy “12 Factor Agents”
The model is the engine. The harness is the car. Nobody buys an engine.
References
Section titled “References”- Anthropic - “Effective Context Engineering for AI Agents” (Sep 2025) anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Anthropic - “Effective Harnesses for Long-Running Agents” (Jan 2026) anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Cursor - “Dynamic Context Discovery” (Jan 2026) cursor.com/blog/dynamic-context-discovery
- Cursor - “Improving Agent with Semantic Search” (2026) cursor.com/blog/semsearch
- Cursor - “Improving Cursor’s Agent for OpenAI Codex Models” (2026) cursor.com/blog/codex-model-harness
- Manus - “Context Engineering for AI Agents: Lessons from Building Manus” (Jul 2025) manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
- LangChain - “Deep Agents” (Jul 2025) blog.langchain.com/deep-agents
- LangChain - “Improving Deep Agents with Harness Engineering” (Feb 2026) blog.langchain.com/improving-deep-agents-with-harness-engineering
- Yang et al. - “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering” (NeurIPS 2024) arxiv.org/abs/2405.15793
- Liu et al. - “Lost in the Middle: How Language Models Use Long Contexts” (TACL 2024) arxiv.org/abs/2307.03172
- Phil Schmid - “Context Engineering for AI Agents: Part 2” (Dec 2025) philschmid.de/context-engineering-part-2
- Cognition - “Devin’s 2025 Performance Review” (2025) cognition.ai/blog/devin-annual-performance-review-2025
- Horthy - “12 Factor Agents” paddo.dev/blog/12-factor-agents
- PromptLayer - “Claude Code: Behind-the-Scenes of the Master Agent Loop” blog.promptlayer.com/claude-code-behind-the-scenes-of-the-master-agent-loop
- Vrungta - “Claude Code Architecture (Reverse Engineered)” vrungta.substack.com/p/claude-code-architecture-reverse
- Honra - “Why AI Agents Need Progressive Disclosure, Not More Data” honra.io/articles/progressive-disclosure-for-ai-agents
- Karpathy - “2025 LLM Year in Review” karpathy.bearblog.dev/year-in-review-2025
- Jannesklaas - “Agent Design Lessons from Claude Code” jannesklaas.github.io/ai/2025/07/20/claude-code-agent-design.html