medium.com - Sparse Attention
Motivation
Section titled “Motivation”Transformers are powerful and versatile models for NLP, but they are limited by the memory and computation requirements of their full attention mechanism, which restricts us from increasing input sequence length. This makes them unsuitable for tasks that require longer contexts, such as question answering, document summarization, or genomic analysis. In this blog post, we learn about Big Bird, a new transformer model that can process sequences of up to 8 times longer than the standard transformer, using a sparse attention mechanism that reduces the computational and memory complexity from quadratic to linear.
Vanilla Attention
Section titled “Vanilla Attention”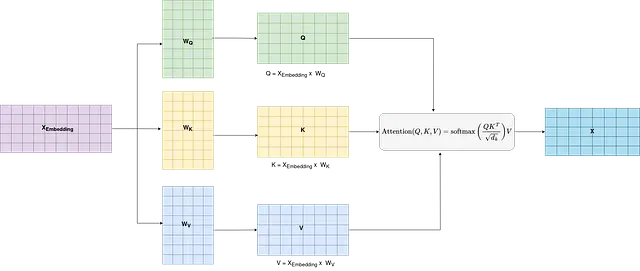
Full attention Mechanism
To delve into the mathematical understanding of attention layers, we need to break down the key components of the attention mechanism, particularly as it is applied in the context of neural networks like the Transformer. Let’s explore the mathematics behind the attention mechanism step by step.
Here, in the above figure we have X_embedding, which is the embedding of our input sentence ( in the figure content length is 5 and embedding dimension is 10).
1. Query, Key, and Value Vectors
Section titled “1. Query, Key, and Value Vectors”Let Q, K, and V be the query, key, and value vectors, respectively, derived from linear projections of the input sequence. Mathematically, this can be represented as:

where:
- X_embedding is the input sequence,
- W_Q, W_K, and W_Vare weight matrices for the query, key, and value projections.
2. Attention Scores
Section titled “2. Attention Scores”After having Q, K, V matrix, the attention scores are computed using the dot product between the query (Q) and key(V) vectors. Further we perform the scaling operation to scale the attention weights by dividing each of the values by sqrt(d). Further, To convert the attention scores into probabilities, the softmax function is applied.
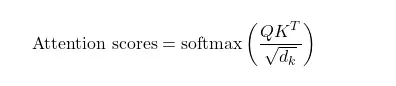
Attention scores is a square matrix of size (context length x context length, here its 5 x 5 ). And this basically involves huge computation and memory overhead while training the models having linger context length.
What does this attention-score matrix signifies?
The attention mechanism allows the model to dynamically weigh and focus on different parts of the input sequence based on the context of the task, improving its ability to capture dependencies and generate more contextually relevant outputs. It can be seen as a way for the model to decide where to “pay attention” in order to make more informed predictions.
4. Weighted Sum
Section titled “4. Weighted Sum”The final step involves taking a weighted sum of the values based on the attention weights. The output of the attention layer is then given by:
Get VISHAL SINGH’s Stories in Your Inbox
Section titled “Get VISHAL SINGH’s Stories in Your Inbox”Join Medium for free to get updates from this writer.
Attention Output = (Attention scores).V
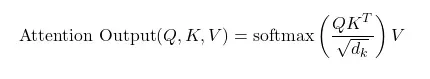
Now since, computation of attention scores are computationally expensive, so the researchers have come with a new mechanism which ease the computation of attention scores, by reducing its time complexity from O(N²) to O(N).
BigBird’s Sparse Attention
Section titled “BigBird’s Sparse Attention”BigBird is a sparse attention mechanism proposed by Google Research that is designed to handle longer sequences more efficiently than traditional attention mechanisms. BigBird’s block sparse attention is a combination of sliding, global, and random connections, allowing each token to attend to some global tokens, sliding tokens, and random tokens instead of attending to all other tokens. This approach significantly reduces the computational cost of attending to all tokens in a sequence, making it possible to handle NLP tasks which need long context length.
Sparse Attention Mechanism in BigBird
Section titled “Sparse Attention Mechanism in BigBird”Let’s say again we have the embedding matrix (Xembedding).
Step 1: Compute Q, K, and V
Section titled “Step 1: Compute Q, K, and V”At first just like the full attention, we first compute Q, K, and V matrix same as before (by taking projection of embedding matrix from corresponding weight matrix).
Step 2: Computation of Attention Scores
Section titled “Step 2: Computation of Attention Scores”Here to understand this well let’s take context length to 10. So according to normal attention we have to compute attention score of size 10x 10, where i-th row of attention matrix denotes the amount of focus the model needs to give on each of the word while processing i-th word.
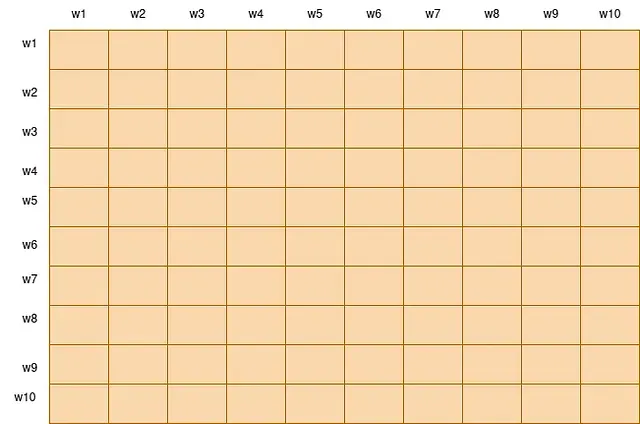
For computing the attention scores, the paper suggest that we not need to compute the attention score of each of the input token corresponding to every token in the query vector. We can compute only some of the attention weights, which will approximate the original attention weights.
So for this calculation of sparse attention weights, we actually compute the attention weights corresponding to three different positions, which are described as follows:
- Global tokens: A set of g tokens that attend to the whole sequence and are attended by all other tokens. These tokens serve as a summary of the sequence and help to propagate information across distant positions. For example, the CLS token and the question tokens in a question answering task can be global tokens.
Since the special tokens attends the whole sequence, we will compute the attention of all the tokens for w1 and w10 (which will be CLS, EOS etc.), thus the first and last row of below metrics will be computed.
Also these special tokens are attended by all the other tokens, thus attention of all the token of w1 and w10 will be computed, for all the words w2 to w9 (thus we will be also computing the first and last column).
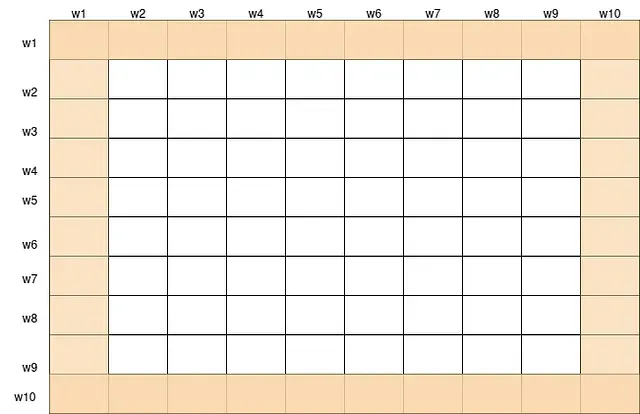
- Window tokens: All tokens attend to a window of w neighboring tokens on each side. This captures the local context and structure of the sequence.
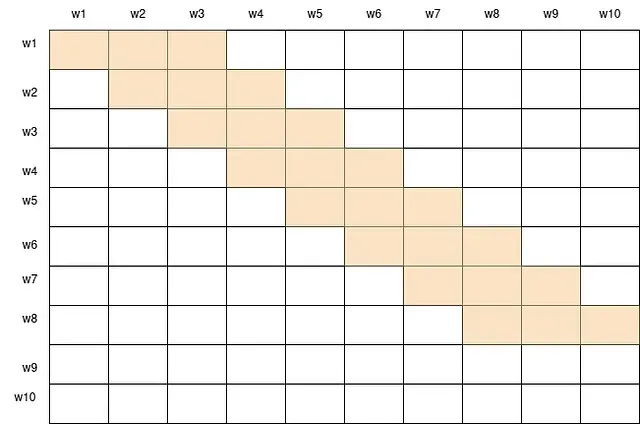
window attention score with window size = 3
- Random tokens: All tokens attend to a set of r random tokens from the sequence. This introduces some randomness and diversity to the attention pattern and helps to connect distant tokens that are not in the same window.
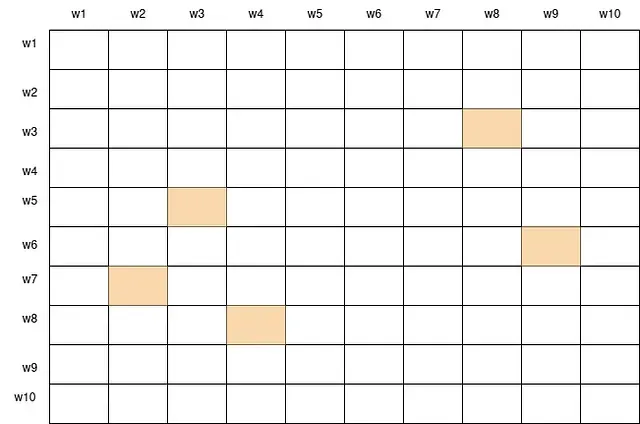
Random attention scores
Now the final attention scores can be obtained by overlapping all these attention scores together.
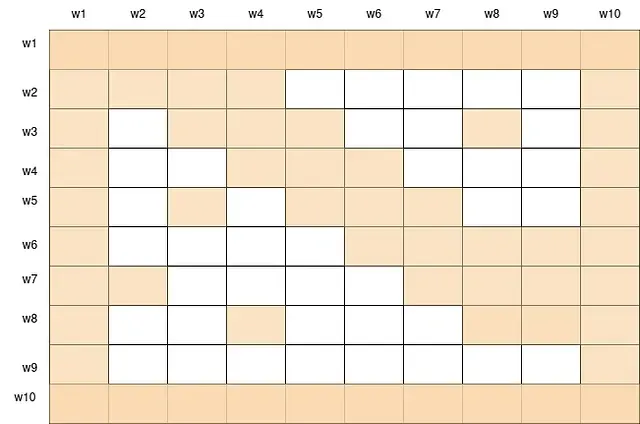
Final attention scores
By combining these three components, Big Bird can achieve a good balance between the average shortest path and the clustering coefficient of the attention graph, which are two important measures of the connectivity and locality of the graph. In other words, Big Bird can efficiently capture both the global and local dependencies in the sequence, without sacrificing the expressiveness and flexibility of the transformer model.
Benefits of BigBird’s Sparse Attention
Section titled “Benefits of BigBird’s Sparse Attention”BigBird has achieved state-of-the-art results in various NLP tasks, such as question answering and document summarization, and has also been applied to genomics data. The model’s efficient implementation of sparse attention has made it a valuable tool for handling long sequences in natural language processing and other domains.The implementation of BigBird’s sparse attention reduced the quadratic increase in computation and memory head of vanilla attention to linear.
References
Section titled “References”- Paper: Bird: Transformers for Longer Sequences
- Blog: https://huggingface.co/blog/big-bird
- Code Video: https://www.youtube.com/watch?v=G22vNvHmHQ0


A professional in the field of data science, machine learning, and GenerativeAI. Currently, I work at Infoedge (Naukri.com) as data scientist.
Responses (2)
Section titled “Responses (2)”Write a responseWhat are your thoughts?
Great article have you read this from Deepseek? https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdfGreat content!